Symmetric matrices arise in many practical contexts: an important one we will spend time on next lecture are covariance matrices. For now, we simply take them as a family of interesting matrices.
Symmetric matrices enjoy many interesting properties, including the following one which will be the focus of this lecture:
We’ll spend the rest of this lecture exploring the consequences of this remarkable theorem, before diving into applications over the next few lectures.
First, we work through a few simple examples to see this theorem in action.
The theorem above tells us that every real, symmetric matrix admits an eigenvector basis, and hence is diagonalizable. Furthermore, we can always choose eigenvectors that form an orthonormal basis—hence, the diagonalizing matrix takes a particularly simple form.
Remember that a matrix Q∈Rn×n is orthogonal if and only if its columns form an orthonormal basis of Rn. Alternatively, we can characterize orthogonal matrices by the condition that QTQ=QQT=I, i.e., Q−1=QT.
If we use this orthonormal eigenbasis when diagonalizing a symmetric matrix A, we obtain its spectral factorization:
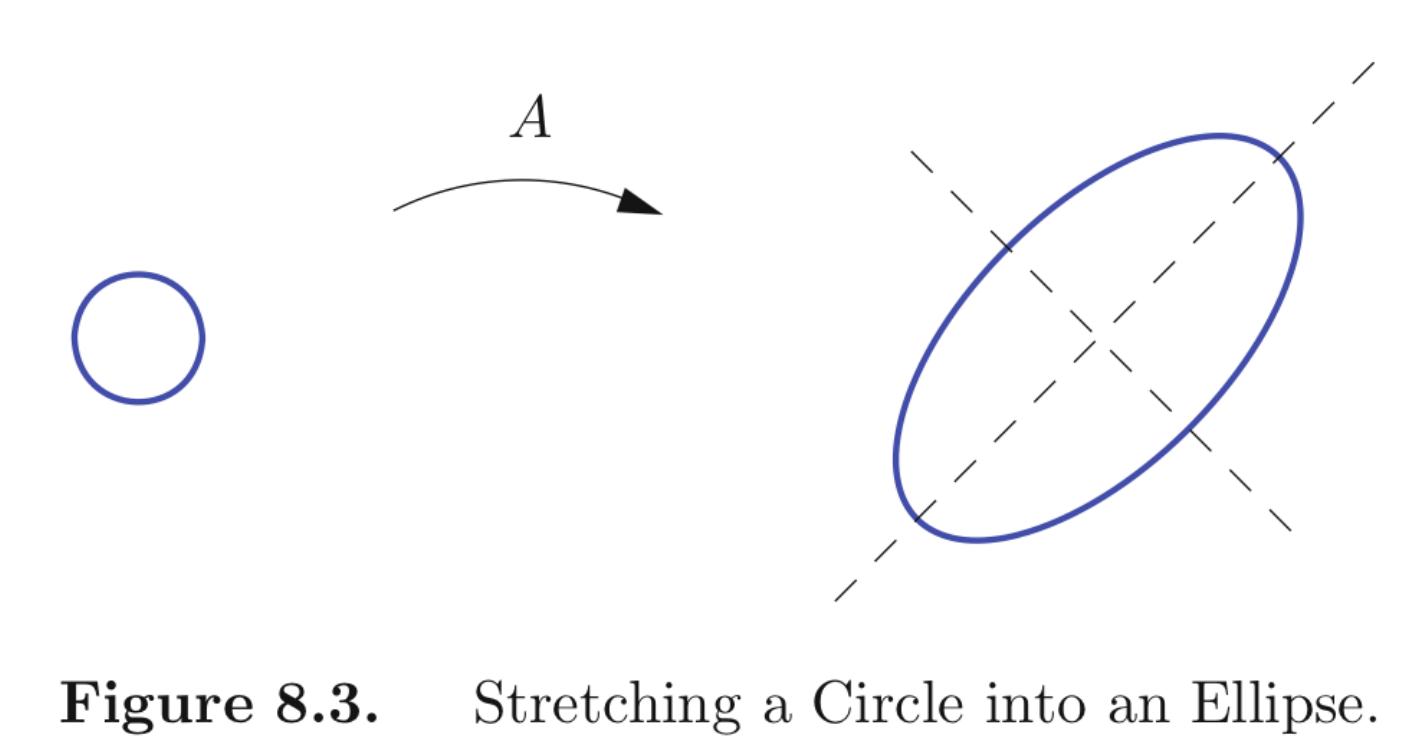
You can always choose Q to have detQ=1; such a Q represents a rotation. Thus the diagonalization of a symmetric matrix can be interpreted as a rotation of the coordinate system so that the orthogonal eigenvectors align with the coordinate axes. Therefore, the linear transformation L(x)=Ax for which A has all positive eigenvalues can be interpreted as a combination of stretches in n mutually orthogonal directions. One way to visualize this is to consider what L(x) does to the unit Euclidean sphere S={x∈Rn∣∥x∥=1}: stretching it in orthogonal directions will transform it into an ellipsoid : E=L(S)={Ax∣∥x∥=1} whose principal axes are the directions of stretch, i.e., the eigenvectors of A.