3.5 Clustering and the K-Means Algorithm
An example of unsupervised machine learning
0.1Reading¶
Material related to this page, as well as additional exercises, can be found in VMLS Chapter 4.
0.2Learning Objectives¶
By the end of this page, you should know:
- the clustering problem
- the centroid, or mean, of a group of vectors
- the K-means algorithm
1The Clustering Problem¶
1.1An Informal Example of Clustering (VMLS 4.1)¶
Suppose we have vectors . The goal of clustering is to group the vectors into groups, groups or clusters of vectors that are close to each other, as measured by the distance between pairs of them.
Normally, the number of groups is much smaller than the total number of vectors . Typical values in practice for range from a handful (2-3) to hundreds, and ranges from hundreds to billions.
The figure below shows a simple example with vectors in , shown as small circles. The right picture shows that is easily seen: these vectors can be clustererd into groups in a way that “looks right” (we will quantify this idea soon).
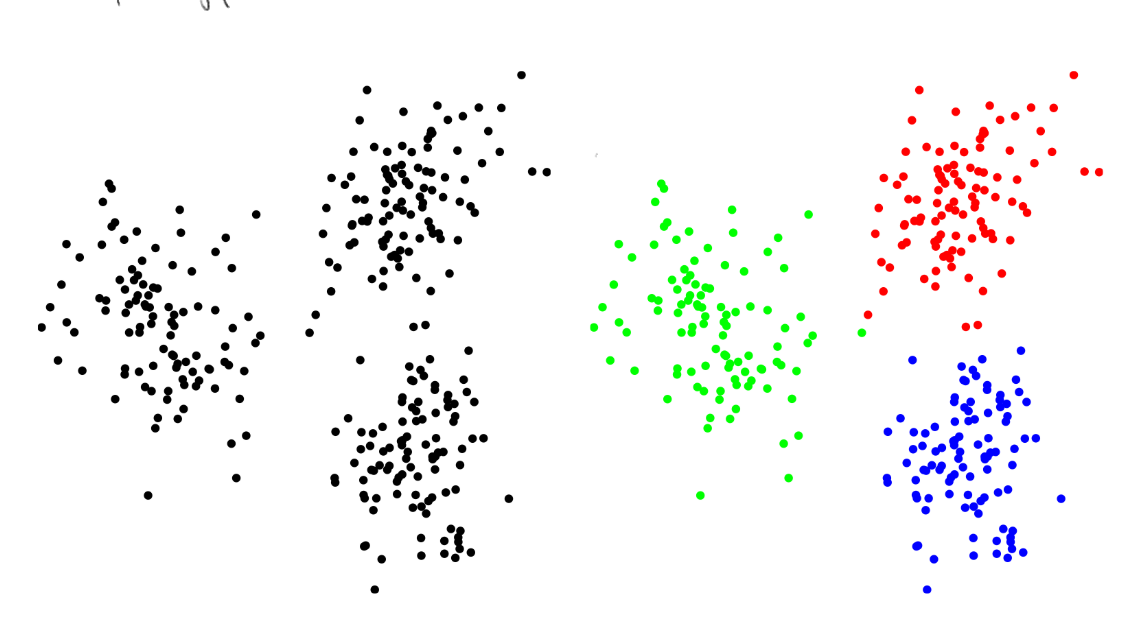
This is example is a bit silly; for vectors in , clustering is easy; just make a scatter plot and use your eyes. In almost all applications, vectors live in with much bigger than 2. Another silly aspect is how cleanly points split into clusters; real data is messy, and often many points lie between clusters. Finally, in real examples, it is not always obvious how many clusters there are.
1.2Applications of Clustering¶
Despite all of this, we’ll see clustering can still be incredibly useful in practice. Before we dive into more details, let’s highlight a few common applications where clustering is useful:
Topic discovery. Suppose are word histograms associated with documents (a word histogram has entries which count the number of times word appears in a document). Clustering will partition the documents into groups, which can be interpreted as groups of documents with the same or similar topics, genre, or author. This is sometimes called automatic topic discovery.
Customer market segmentation. Suppose the vector gives the dollar values of items purchased by customer in the past year. A clustering algorithm groups the customers into market segments, which are groups of customers with similar purchasing patterns.
Other examples include patient, zip code, student, and survey response clustering, as well as identifying weatehr zones, daily energy use patterns, and financial sectors. See pp. 70-71 of VLMS for more details.
1.3A Clustering Objective (VLMS 4.2)¶
Our goal now is to formalize the ideas described above, and introduce a quantitative measure of “how good a clustering” is.
Specifying Cluster Assignments¶
We specify a clutering of vectors by assigning each vector to a group. We label the groups and assign each of the vectors to a group via the vector , with being the group number that has been assigned to.
For example, if and , then
assigns to group 3; to group 1; to group 2.
We will also describe clusters by the sets of indices for each group, with being the set of indices associated with group . For our simple example, we have
In general, we have that .
Group Representatives¶
Each group is assigned a group representative . Note that these representatives can be any vector, and need not be one of the given vectors . A good clustering will have each representative close to vectors in its associated group, i.e.,
is small for all . Note that according to our notation, is in group , so is the group representative against which should be measured.
A Clustering Objective¶
We now define a clustering objective that assigns a score, or cost, to a choice of clustering and representatives:
A clustering is said to be optimal if the choice of group assignments and group representatives lead to the smallest achievable clustering objective ; in this case, these choices are said to minimize the objective . Unfortunately, except for very small problems, it is computationally prohibitive to find an optimal clustering.
Forutunately, the k-means algorithm we will introduce next can be run efficiently on very large problems, and often finds very good clusterings that achieve objective values near the smallest possible value. Because k-means finds suboptimal solutions, we call it a heuristic. Heuristics are often looked down on in more theory oriented circles because they cannot guarantee the quality of their solutions, but as we will see, they often work incredibly well in practice!
2The K-Means Algorithm¶
The idea behind k-means is to break down the overall hard problem of choosing the best representatives and clusterings at the same time into two subproblems we can easily solve effectively. While we can’t yet solve the problem of jointly choosing group assignments of group representatives to minimize , we know how to solve for one component when the other is fixed.
2.1Partitioning Vectors with Representatives Fixed¶
Pretend for a moment that we have already found group representatives , and our task is to pick the group assignments which lead to the smallest possible . This problem is actually very easy! We will use the idea of nearest neighbors we saw in the previous section.
Notice that the objective is a sum of terms, with one term for each vector . Further, the choice of (i.e., the group to which we assign ) only affects the term
in . This means we should choose to make this term smallest since it doesn’t affect any other terms in our clustering objective. To minimize , we pick the so that
This should look familiar! Modulo our new notation, we should asign to its nearest neighbor among the representatives.
2.2Optimizing the Group Representatives with Assignments Fixed¶
Now we flip things around, and assume each vector has been assigned to a group . How should we pick group representatives to minimize ? We start be rearranging our objectives into sums, one for each group:
where is the contribution to from the vectors in group . The sum notation here means we should include terms in our sum if (i.e., if has been assigned to group ).
The choice of representative only affects the term , so we can choose to minimize . You can check, e.g., using vector calculus, that the best choice is to pick to be the average (or centroid) of the vectors in group :
Here is the cardinality of the set , and denotes the number of elements in the set , i.e., the size of group .
2.3Pseudocode for the k-means Algorithm¶
While we can’t yet solve the problem of jointly choosing group assignments & group representatives , we know how to solve for one component when the other is fixed.
The k-means algorithm produces an approximate solution to the clustering problem by iterating between the two subroutines. A key feature of this approach is that gets better or stays the same with each iteration, meaning it is guaranteed to converge, to a (likely suboptimal) solution.
We next state the pseudocode for the k-means algorithm.
One iteration of the k-means algorithm is illustrated below:
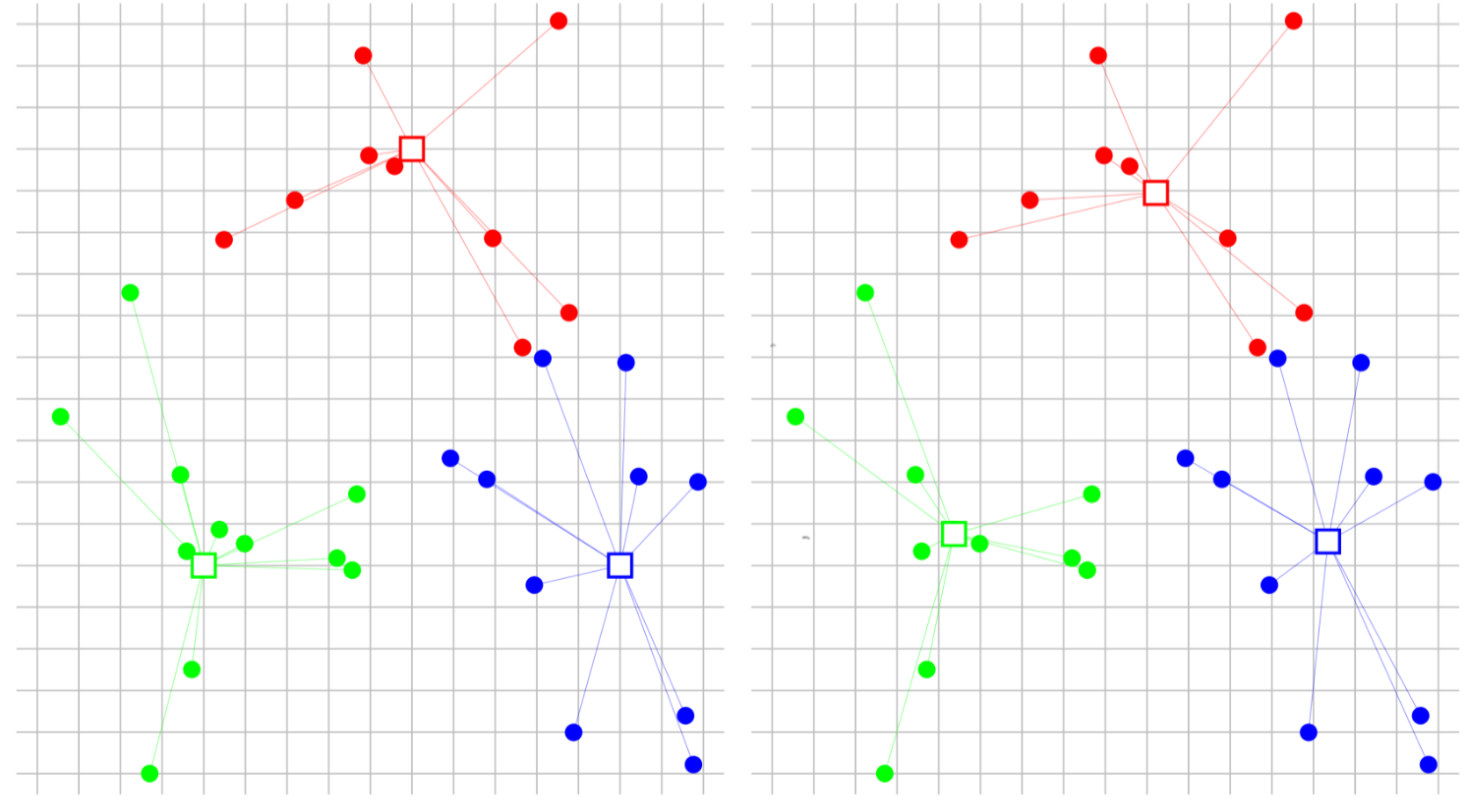
Left: vectors are assigned to the nearest representative .
Right: the representatives are updated to the centroids of the new groups.
3Python break: K-Means in scikit-learn!¶
The scikit-learn library in Python gives an implementation of the k-means algorithm. Documentation is available here.
In the following code, we generate a sample clustering problem with and . We then run k-means, plot some intermediate clusterings, and plot the final clustering. We also plot the rate of convergence (k-means loss vs. number of iterations).
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
np.random.seed(2030)
# Sample data
sample1 = np.random.multivariate_normal(
mean=np.array([2, 0]),
cov=np.array([[2, 0], [0, 2]]),
size=300
)
sample2 = np.random.multivariate_normal(
mean=np.array([-1, 4]),
cov=np.array([[2, 0.5], [0.5, 1]]),
size=180
)
sample3 = np.random.multivariate_normal(
mean=np.array([-3, -2]),
cov=np.array([[1, -0.2], [-0.2, 2]]),
size=120
)
# Generates a dataset with data sampled from 3 normal distributions.
data = np.concatenate((sample1, sample2, sample3), axis=0)
initial_representatives = [[5, 0], [4.5, 0], [4, 0]]
# Define RGB colors for the clusters.
colors = np.array([
[1, 0, 0],
[0, 1, 0],
[0, 0, 1]
])
fig, axes = plt.subplots(5, 1, figsize=(20, 20))
# For demonstration purposes, we will purposely limit the number of k-means iterations
# and show you the outputs along the way!
num_iterations = [1, 2, 6]
for i in range(len(num_iterations)):
kmeans = KMeans(n_clusters=3, random_state=0, init=initial_representatives, max_iter=num_iterations[i]).fit(data)
ax = axes[i]
ax.scatter(data[:, 0], data[:, 1], c=colors[kmeans.labels_], s=5)
ax.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], marker='x', c='black', s=100)
ax.set_title(f'K-Means with {num_iterations[i]} Iterations')
ax.set_aspect('equal')
ax.set_xticks([])
ax.set_yticks([])
# Now, we allow the algorithm to run until convergence and plot the clusters.
kmeans = KMeans(n_clusters=3, random_state=0, init=initial_representatives).fit(data)
ax = axes[3]
ax.scatter(data[:, 0], data[:, 1], c=colors[kmeans.labels_], s=5)
ax.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], marker='x', c='black', s=100)
ax.set_title(f'Final Clustering')
ax.set_aspect('equal')
ax.set_xticks([])
ax.set_yticks([])
# We also run the code again for a bunch of different iteration numbers, and plot the
# rate of convergence to the solution.
costs = []
for i in range(kmeans.n_iter_):
kmeans = KMeans(n_clusters=3, random_state=0, init=initial_representatives, max_iter=i+1).fit(data)
costs.append(kmeans.inertia_ / data.shape[0])
ax = axes[4]
ax.plot(range(1, kmeans.n_iter_ + 1), costs, marker='o', linestyle='-', color='b')
ax.set_title('Rate of Convergence of K-means')
ax.set_xlabel('Iteration')
ax.set_ylabel('Cost (Mean Squared Distance)')
ax.set_aspect('equal')
ax.set_xticks(range(1, kmeans.n_iter_ + 1))
ax.set_yticks([])
plt.tight_layout()
plt.show()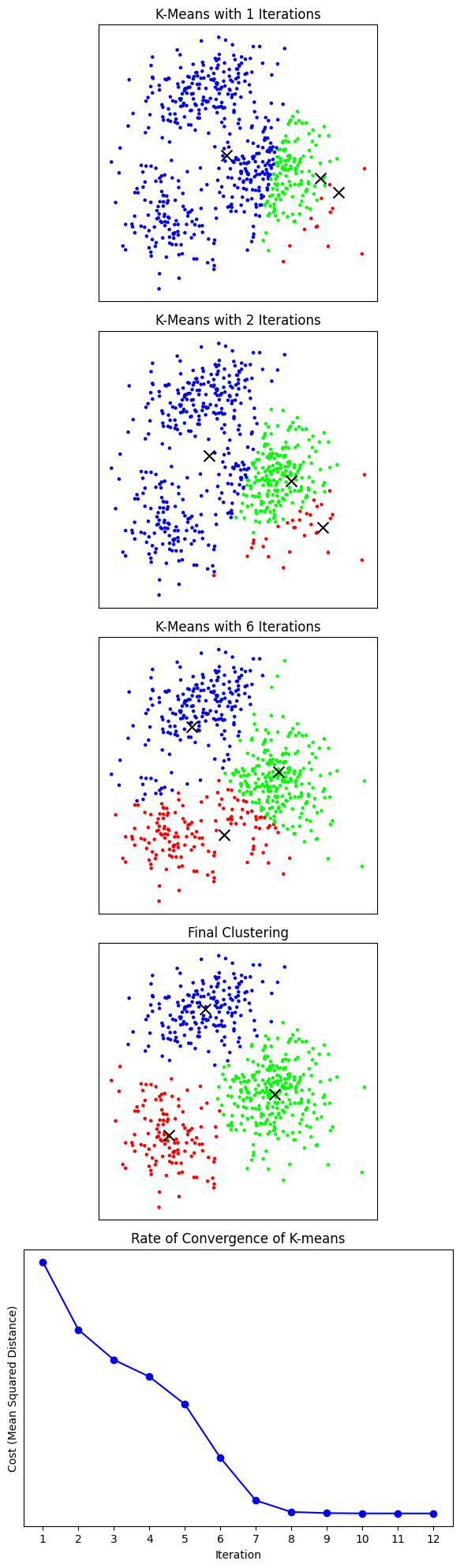
4Python Break: Automated Topic Discovery!¶
TODO
