3.6 Case Study: Handwritten Digit Recognition with K-Means
Computing distances between handwritten numbers

K-means falls into the category of unsupervised machine learning algorithms, or algorithms which take a dataset and output patterns from that dataset. K-means, being a clustering algorithm, extracts clusters from a dataset of vectors. This is in contrast to supervised machine learning algorithms, which take a dataset consisting of input-output pairs, and try to learn a function mapping inputs to outputs.
In this case study, we’re going to apply the k-means algorithm to a dataset consisting of 1797 handwritten digits. Our objective is to identify groups of similar digits. To that end, we will:
use k-means to group these digits into 20 clusters,
visualize the clustering representatives,
measure how well k-means clustered different digits,
measure which pairs of digits k-means did well/poor in differentiating.
1The UCI-Test Dataset¶
The UCI-Test dataset is a dataset consisting of 1797 handwritten digits, which are represented by pixel greyscale images. A few examples of images from the dataset are below:

Although not pictured above, the UCI-Test dataset is actually a labeled dataset, which means it contains input-output pairs (where the inputs are the images and the outputs are what digit an image represents). We can load the dataset, which conveniently comes with the scikit-learn library, as follows:
from sklearn.datasets import load_digits
digits = load_digits()
print(digits.data.shape)
print(digits.target.shape)(1797, 64)
(1797,)
The digits.data variable is an 1797-by-64 matrix representing a collection of 1797 8-by-8 images; each column of this matrix has 64 entries and represents a “flattened” 8-by-8 image (where each block of 8 entries represents a column of the image).
The digits.target variable is a vector with 1797 entries representing the human-given labels (an integer from 0 to 9) of the corresponding image. For example, digits.target[0] is the digit value of digits.data[0, :].
2Clustering the Images with K-Means¶
K-means, as an unsupervised learning algorithm, does not require knowledge of the labels. Instead of learning to predict whether an image is a zero, one, two, etc. (which requires knowledge of the labels), k-means groups similar images together, and hence only needs the digits.data variable.
The clustering can be performed with the scikit-learn library, as we did in the previous section. Notice that we chose to use 20 clusters, even though there are only 10 digits; in practice, the number of clusters is often unknown.
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=20, random_state=10)
clusters = kmeans.fit_predict(digits.data)
kmeans.cluster_centers_.shape(20, 64)The result is 20 clusters in 64 dimensions. Notice that the cluster centers themselves are 64-dimensional points, and can themselves be interpreted as the “typical” digit within the cluster.
2.1Visualizing cluster centers¶
Let’s see what these cluster centers look like:
import matplotlib.pyplot as plt
fig, ax = plt.subplots(2, 10, figsize=(8, 3))
centers = kmeans.cluster_centers_.reshape(20, 8, 8)
for axi, center in zip(ax.flat, centers):
axi.set(xticks=[], yticks=[])
axi.imshow(center, interpolation='nearest', cmap=plt.cm.binary)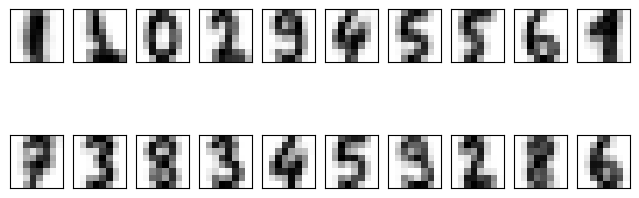
We see that even without the labels, k-means is able to find clusters whose centers are recognizable digits, with perhaps the exception of 1 and 9.
2.2Labeling the cluster centers¶
We emphasize that k-means does not know the true identity of each cluster, because it was never given the labels. We can fix this by matching each learned cluster with the true labels found in them. In this example, we choose to match each cluster to the label it contains the most of (remember that the labels are given in digits.target):
import numpy as np
from scipy.stats import mode
labels = np.zeros_like(clusters)
for i in range(20):
mask = (clusters == i)
labels[mask] = mode(digits.target[mask])[0]3Measuring the Accuracy of a Clustering¶
Now we can check how accurate our unsupervised clustering was in finding similar digits within the data. The accuracy_score function below just takes a list of predictions and a list of labels, and finds the proportion of indices where the prediction equals the label:
from sklearn.metrics import accuracy_score
print(accuracy_score(digits.target, labels))0.9098497495826378
With just a simple k-means algorithm, we discovered the correct grouping for 90% of the input digits!
3.1Forming a confusion matrix¶
To understand where the k-means algorithm failed to differentiate digits, we can use a confusion matrix. In our setting, the confusion matrix is a 10-by-10 matrix detailing how often k-means predicted that a digit belonged to a cluster with label :
import seaborn as sns; sns.set()
from sklearn.metrics import confusion_matrix
mat = confusion_matrix(digits.target, labels)
sns.heatmap(mat.T, square=True, annot=True, fmt='d', cbar=False,
xticklabels=digits.target_names,
yticklabels=digits.target_names)
plt.xlabel('true label')
plt.ylabel('predicted label')
plt.show()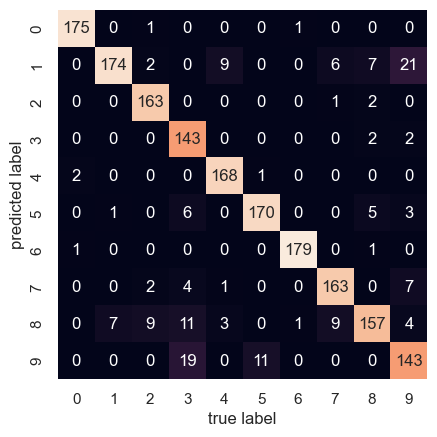
In the above confusion matrix, for example, the cell corresponding to a predicted label of 7 and a true label of 3 contains a value of 4. This indicates that k-means put 4 sevens in clusters which ended up being labeled as threes. The diagonal entries of this confusion matrix represent correctly classified images.
Of interest is the fact that the highest off-diagonal entry, 21, corresponded to one and nine, which is consistent with the cluster centers we visualized before.
Overall, an accuracy of 90% shows that using k-means, we can essentially build a digit classifier without reference to any known labels!