There were a few times during the semester where we tried to find the
“best” vector (or matrix) among a collection of many such vectors or matrices. For example, in least squares, we looked to find the vector x that minimized the expression ∥Ax−b∥2. In low-rank approximation, we looked to find the matrix M^ that has rank k (or less) that minimized the expression ∥M^−M∥F2.
These were both specific instances of what is called a mathematical optimization problem. We will focus on unconstrained problems. You will learn a lot more about optimization problems in ESE 3040, and this lecture is only meant to give you a small taste, and to show how essential linear algebra is in finding solutions.
Optimization problem (1) is called unconstrained because we are free to pick any
x∈Rn we like to minimize f(x). A constrained optimization problem has the additional requirement that x must satisfy some added conditions, e.g., live in the solution set
of Ax=b. We will not consider such problems in this lecture, but you’ll see many in ESE 3040.
The goal of optimization is to find a special decision variable x∗ for which the cost function f is as small as possible, i.e., such that
Equation (3) simply says in math that x∗ satisfies the definition (2) of an optimal point.[1]
Despite how simple and innocuous problem (1) looks, it can be used to encode very rich and very challenging problems. Even for x∈R, we can get ourselves
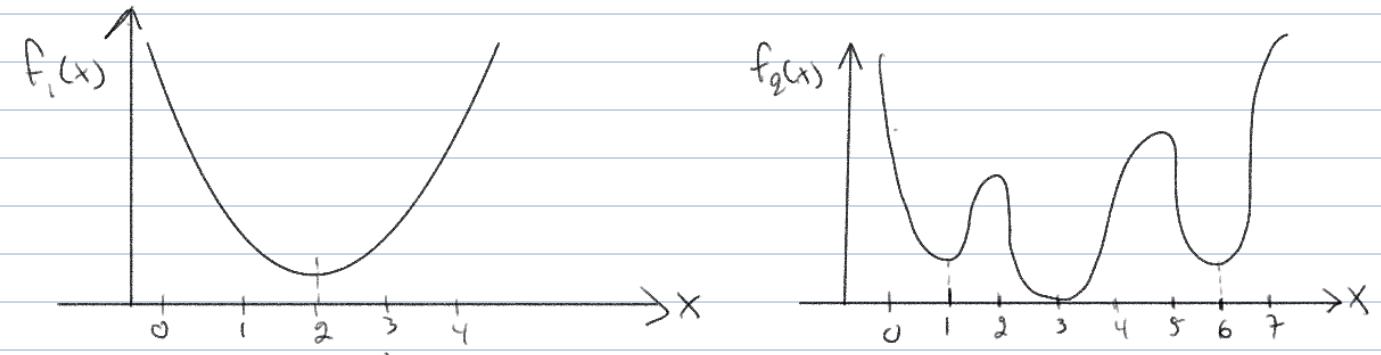
into trouble. Consider the following two functions that we wish to minimize:
Which do you think is easier to optimize? The left figure, with function f1(x), is “bowl-shaped” and is smallest at x∗=2. What’s “nice” about f1 is that there’s also an obvious
algorithm for finding x∗=2: If you imagine yourself as an ant standing on the function f1(x), all you need to do is “walk downhill” until you eventually find the bottom of the bowl.
In contrast, the right figure with function f2(x) has many hills and valleys. The optimal value x∗=3 is the one for which f2(x) is smallest. But now if we again imagine ourselves as an ant standing on the function f2(x), our strategy of walking downhill will not always work! For example, if we were to start at x=1.5, then walking downhill would bring us to the bottom of the first valley at x=1. Now x=1 is not an optimal point, since f2(3)<f2(1), but if we look around at nearby points, then f2(1) is indeed the smallest.
As you may have guessed, we really like “bowl-shaped” functions for which our walking downhill strategy finds a global minimum. Such functions satisfy a geometric property called convexity.
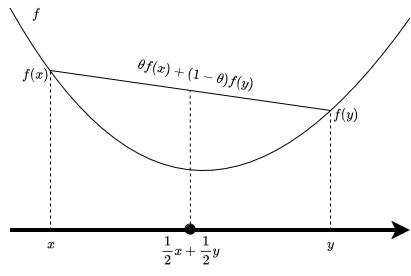
To understand what (CVX) is saying, it is best to draw what it means for a scalar
function f:R→R.
(CVX) says that if I pick any two points f(x) and f(y) on the graph, and draw a line segment between these two points, then this line lies above the graph. It turns out that this is exactly the right way to mathematically characterize “bowl-shaped” functions, even when x∈Rn. The important feature of convex functions is that “walking
downhill” will always bring us to a global minimum. We won’t say much more about convex functions, but you’ll see them again in ESE 3040, and there is a graduate level course, ESE 6050, which focuses entirely on convex optimization problems.
A more formal way of making the argument in Example 3 is to show that the Hessian ∇2f(x) of f is positive semidefinite. Here ∇2f(x)=2ATA, which is indeed positive semidefinite. This is the matrix/vector equivalent of saying that f(x)=a2x+bx+c is an upward pointing bowl if and only if a≥0.
If you don’t remember what the Hessian ∇2f(x) of a function is, or how we computed ∇2f(x)=2ATA in the above, don’t worry, we’ll review this in a bit.
Let’s assume that we are either in a “nice” setting where our objective function is convex (bowl shaped), or that we’re happy to settle for a local minimum. How can we figure out which way is down so that we can tell our little ant friend which way they should walk. To get some intuition, we will start with with functions with x∈R2 and look at some cost function contour plots.
Let’s start with two familiar examples:
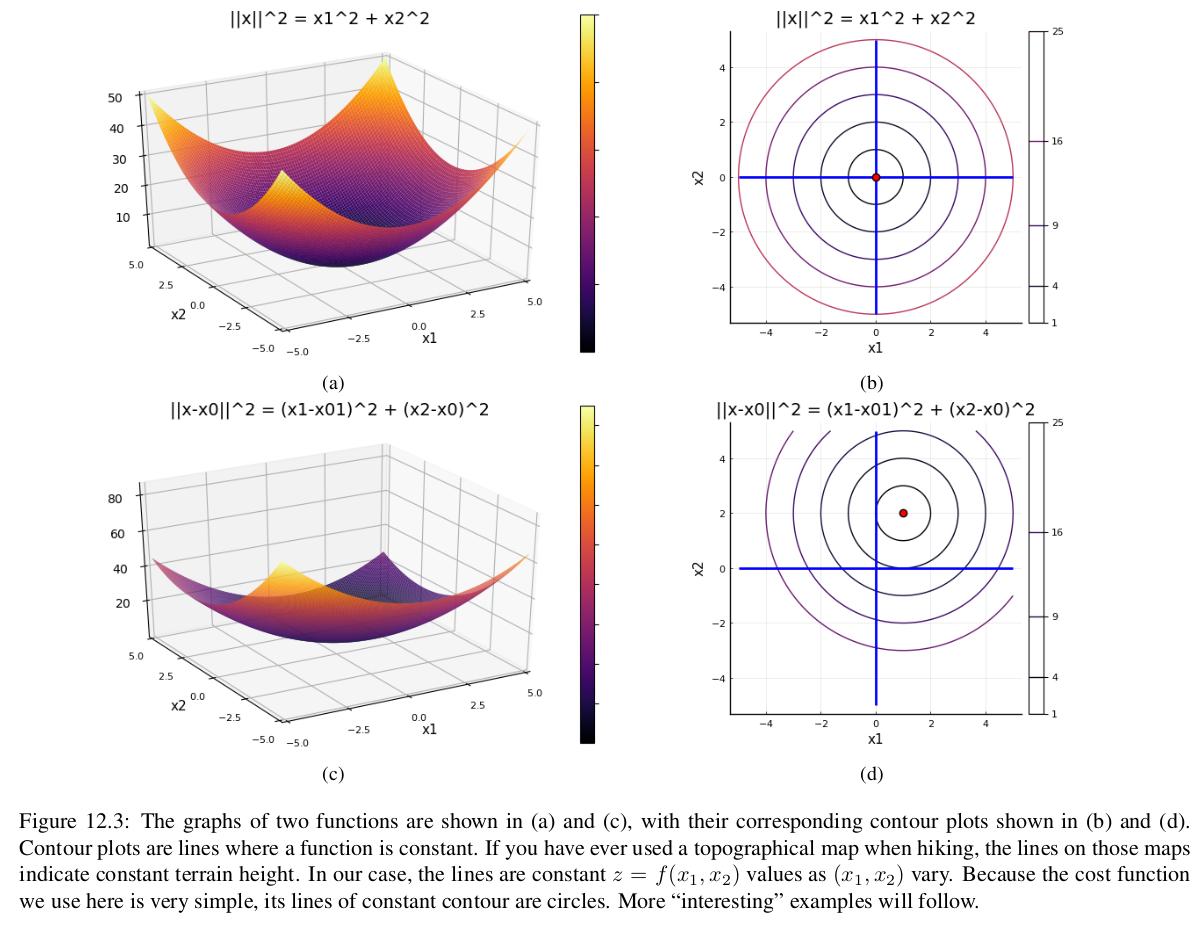
f(x)=∥x∥2=x12+x22, which is nothing but the Euclidean norm squared of x, and
f(x)=∥x−b∥2=(x1−b1)2+(x2−b2)2, which is a very simple least squares objective with A=I.
We have plotted both of these functions, and their contour plots, below:
The contour plots show the level sets of f(x), which we’ve seen before. These are the sets Cα={x∈R2∣f(x)=α} for some constant α. Here, these end up being circles, since for example C1 is the set of x1,x2 such that x12+x22=1 or (x1−b1)2+(x2−b2)2=1.
Can we use these contour plots to identify which way is down if our ant is currently sitting at point w∈R2?
To answer this question, we’ll need the gradient ∇f(x) of our function. Recall from Math 1410 that for a function f:Rn→R, its gradient ∇f(x) is an n-vector of the partial derivatives of f:
For our functions on R2, this reduces to ∇f(x)=(∂x1∂f(x1,x2),∂x2∂f(x1,x2))∈R2.
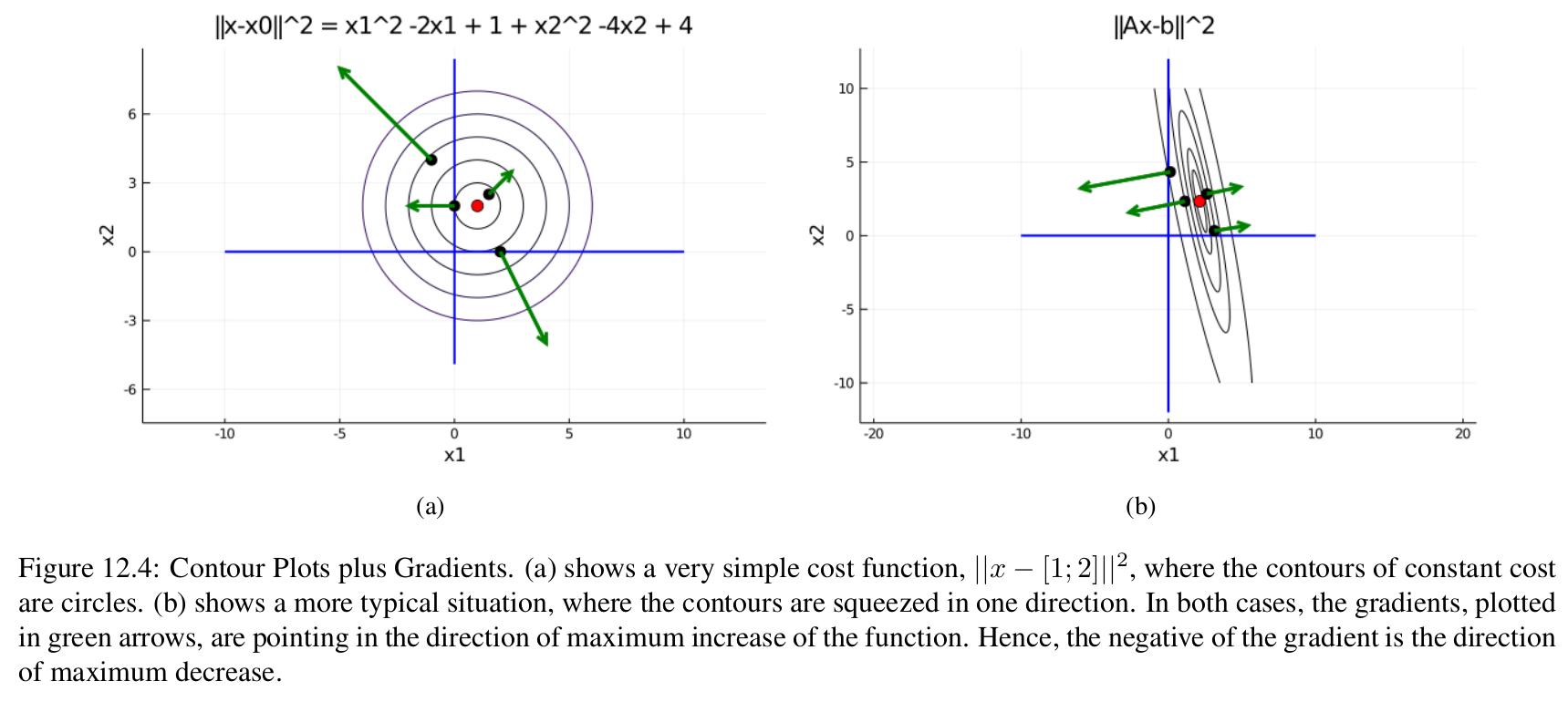
In the figure below, we show contour plots for f1(x)=∥x−b∥2=(x1−1)2+(x2−2)2 and f2(x)=∥Ax−b∥2, along with the gradients ∇f(x) (green arrows) at various points.
In both cases, the gradients are pointing in the direction of maximal increase: if we go in the opposite −∇f(x) direction, we will move in the direction of maximal decrease!
Let’s flex our calculus muscles a bit and compute the gradients of f(x) and f2(x)[2]:
One thing you might notice in the plots above is that the red dots, which we placed on the function minimum, have no green arrows. This is because the gradient at these points is zero. In fact, this is true in general: a point x is a local minimum only if∇f(x)=0.
We won’t prove this, but intuitively, this makes sense: if ∇f(x)=0, then this means there is a direction −∇f(x) in which I could walk a little bit downhill to decrease f(x), so ∇f(x) must be zero if we’re at a local minima. Let’s check that this holds for ∇f1(x) and ∇f2(x) above:
For f1(x), x∗=(1,2), and ∇f1(x∗)=2[x1∗−1x2∗−2]=0, and so that checks out. And for f2(x), x∗=(ATA)−1ATb, and
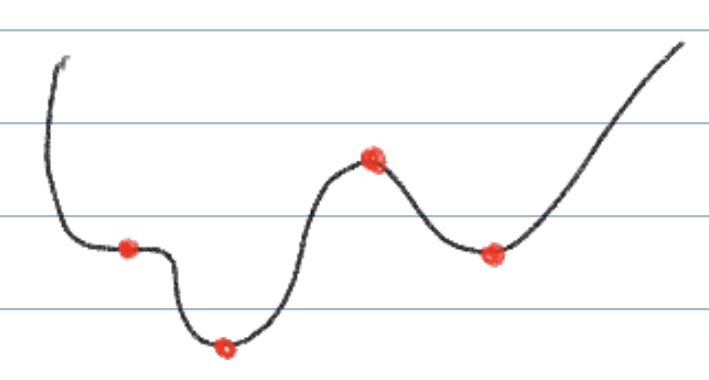
In general, while ∇f(x∗)=0 is necessary for x∗ to be a local minima, it is not sufficient, i.e., there may be certain points with ∇f(x∗)=0 that are not local minima. For example, all red dots in the plot below have vanishing gradients, but only two are minima:
However, if our function f is convex (bowl shaped), we have the following theorem which tells us that walking downhill will always find a global minimum:
Next, we’ll use our new found insights to define gradient descent, a widely used iterative algorithm for finding local minima of optimization problem (1).
If you don’t know how to compute this gradient, you may wish to review Math1410 notes, but don’t worry, we won’t ask you to calculate gradients on the homework & exams.