13.2 Gradient Descent
1Reading¶
Material related to this page, as well as additional exercises, can be found in Chapter 12 in ROB101 textbook by Jesse Grizzle
2Learning Objectives¶
By the end of this page, you should know:
- what is the gradient descent algorithm
- examples of implementing the gradient descent algorithm
- what is exact line search
- when does gradient descent perform poorly and how to address it
3Introduction¶
Our intuition so far is that we should try to “walk downhill” and that the negative gradient tells us the steepest direction of descent at point . Can we turn this into an algorithm for minimizing (at least locally) a cost function ?
This intuition is precisely the motivation behind the gradient descent algorithm, which starting with an initial guess , iteratively updates the current best guess of according to:
where is called the step size. The update rule (GD) moves you in the direction of a local minimum if , but be careful, because if is too large, you can overshoot (we’ll see more about this later).
Because we know that if is a local minima, we can use the norm of the gradient as a stopping criterion, i.e., if for some small , we stop updating our iterate because is “close enough” to (typical choice of ε are 10-4 or 10-6, depending on how precise of a solution is required).
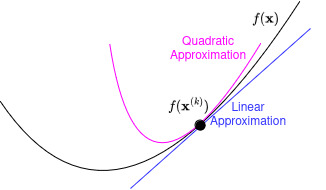
Before looking at some examples of (GD) in action, let’s try to get some intuition as to why it might work. Suppose we are currently at : let’s form a linear approximation of near using its first-order Taylor series approximation:
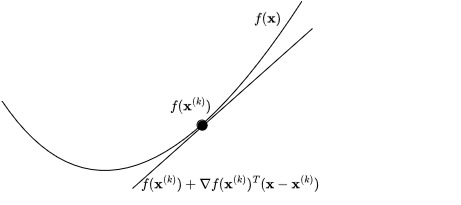
As you can see from the figure, (TS) is a very good approximation of when is not too far from , but gets worse as we move further away.
Let’s use (TS) to define our next point so that . If we define , then evaluating (TS) at point becomes
so that if we want , then we should find a nearby such that
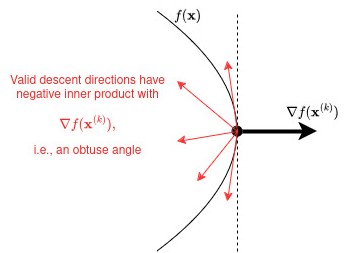
Now, assuming that (so we’re not at a local extremum), a clear choice for is for a step size chosen small enough so that (TS) is a good approximation. In that case, we have
In general though, any choice such that (4) holds is a valid descent direction. Geometrically, this is illustrated in the picture below:
3.1Python Break!¶
In this section, we’ll take a look how step sizes can affect convergence of the gradient descent algorithm through a few Python examples. We’ll take a look at a less trivial least-squares objective, where we randomly generate a (rectangular) matrix and vector and optimize the least-squares objective with respect to . We’ll consider 2 choices of step sizes, and plot the convergence of the objective value with the number of iterations of gradient descent:
Large step size of
Small step size of
The convergence is shown by the log-suboptimality plot, which plots as a function of . Faster converging step sizes are indicated by a more steeply decreasing function on the log-suboptimality plot.
import numpy as np
import matplotlib.pyplot as plt
# Generate random matrix A and vector b
np.random.seed(42)
A = np.random.randn(100, 50)
b = np.random.randn(100)
# Objective function: ||Ax - b||^2
def objective_function(x):
return np.linalg.norm(A @ x - b) ** 2
# Gradient of the objective function
def gradient(x):
return 2 * A.T @ (A @ x - b)
# Gradient descent function
def gradient_descent(A, b, eta, num_iterations):
x = np.zeros(A.shape[1]) # Initialize x to zero
obj_values = []
f_star = objective_function(np.linalg.pinv(A) @ b) # Best achievable value (for log suboptimality)
for _ in range(num_iterations):
obj_values.append(objective_function(x))
grad = gradient(x)
x -= eta * grad # Update x using gradient descent
# Compute log suboptimality
log_suboptimality = np.log10(np.array(obj_values) - f_star + 1e-10) # Small epsilon to avoid log(0)
return log_suboptimality
# Set number of iterations
num_iterations = 100
# Define a range of step sizes to try
etas = [0.0036, 0.0035, 0.001, 0.0005, 0.0001]
# Plot the results for each step size
plt.figure(figsize=(12, 6))
for eta in etas:
log_suboptimality = gradient_descent(A, b, eta, num_iterations)
plt.plot(log_suboptimality, label=f'eta={eta}')
plt.xlabel('Iteration')
plt.ylabel('Log Suboptimality')
plt.title('Convergence of Gradient Descent with Different Step Sizes')
plt.legend()
plt.grid(True)
plt.show()
print('1 / maximum eigenvalue of A.T @ A:', 1 / max(np.linalg.eig(A.T @ A).eigenvalues))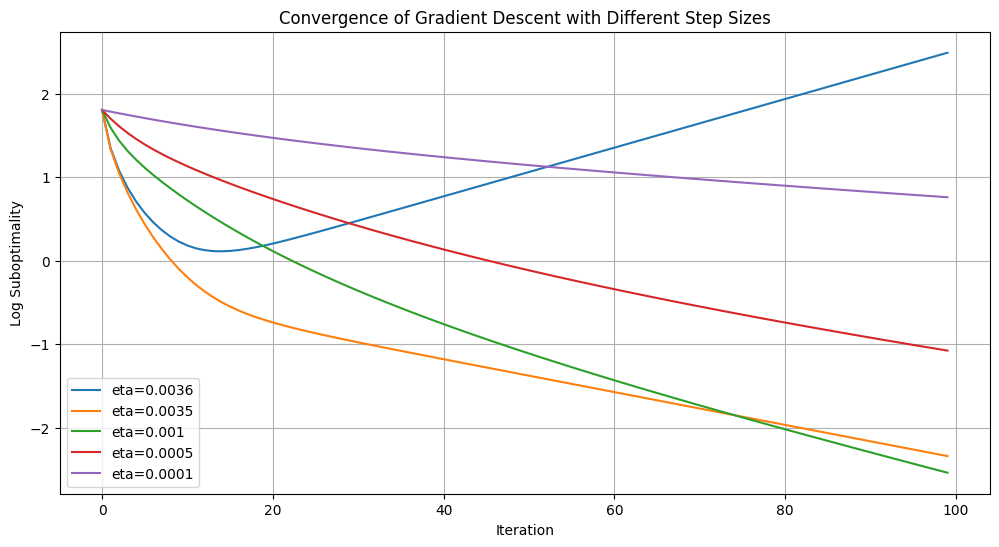
1 / maximum eigenvalue of A.T @ A: 0.0035395895131759892
There are a few observations we can make from the graph. First, note that when the step size η is very small, then the gradient descent converges to the minimum, but at a slow rate, as indicated by the purple curve. Second, note that by gradually increasing η (up until a point), we can achieve faster convergence, as indicated by the purple, red, and green curves. Third, however, note that after we increase η too much, the convergence starts to get slower and if we increase η enough, then gradient descent actually diverges, as indicted by the orange and blue curve.
As a cool and optional final note, we also printed the inverse of the minimum eigenvalue of A.T @ A, which is . Note that it is between the step sizes of 0.0036 and 0.0035, which represent the boundary where gradient descent starts to diverge; this is no coincidence! For those who are familiar with Lipschitz continuity, the objective function has Hessian , meaning that its first derivative is Lipschitz-continuous in with with a Lipschitz constant of (the maximum eigenvalue of ). It turns out that when the step size is chosen such that , then gradient descent is guaranteed to converge! A proof of this fact can be found here.
4Zig-zags and What to do About Them¶
Let’s consider a very simple optimization over with cost function
where we’ll let vary. The optimal solution is obviously but we’ll use this to illustrate how gradient descent can get you into trouble sometimes.
Suppose we run gradient descent on , and we further allow ourselves to pick the best possible step size at each iteration, i.e., we choose step size
and then update .
This is called exact line search for selecting the step size, and is widely used in practice. If we use this choice of step size , then it is possible to write an explicit formula for our iterates as we progress down the bowl. Starting at , we get
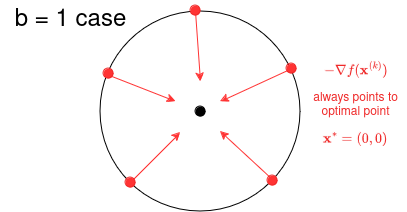
If , which corresponds to a function with level sets that are perfect circles, we succeed immediately in one step . This is because the gradient always points directly to the optimal point :
The real purpose of this example is seen when is small. The crucial ratio in equation (10) is
If is small, converges to very quickly. However, if is close to 1, then this convergence is very slow. For example, if , then ; for , .
This means we need to take many more gradient steps to get close to . The picture below highlights what’s going wrong: for small , the level sets become elongated ellipses, so that following gradients leads to us zig-zagging our way to the origin instead of taking a straight path. It is this zig-zagging that causes slow convergence.
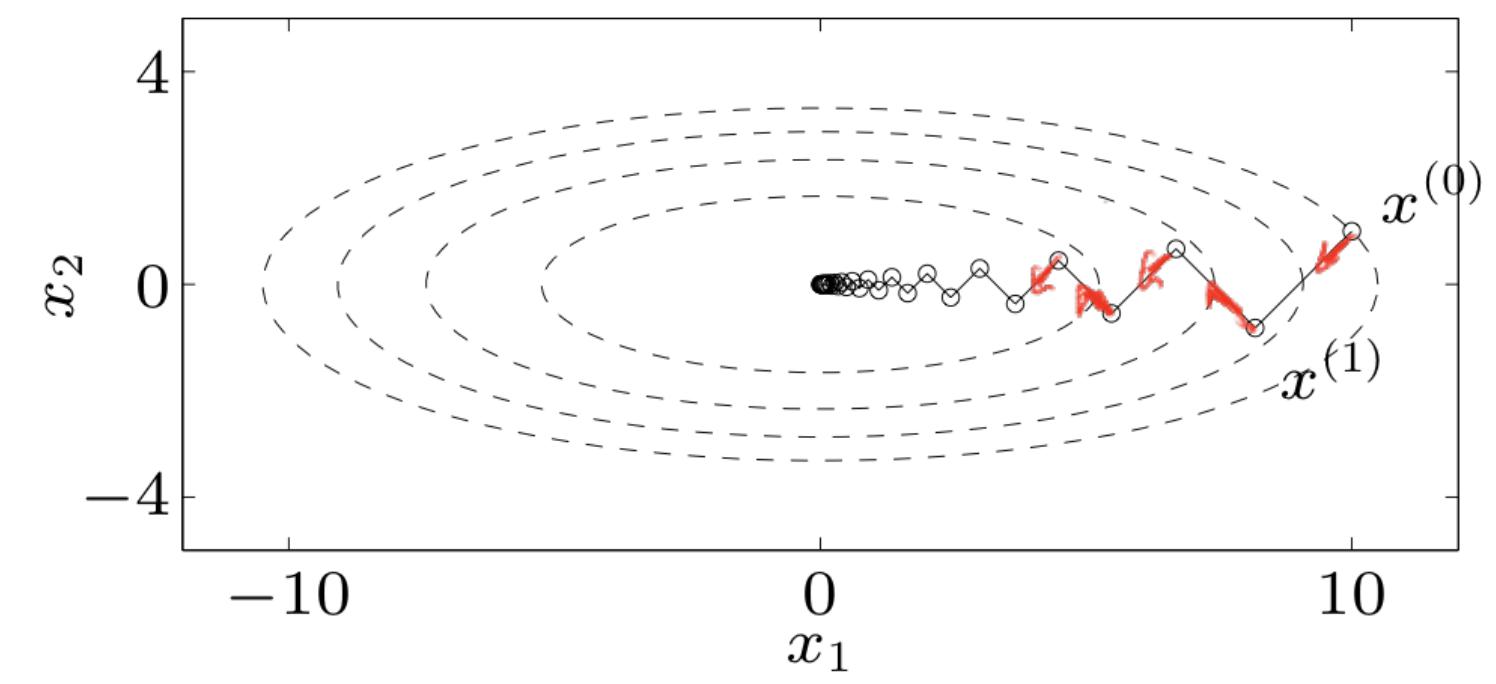
So what’s going wrong here? If we write as a quadratic form, it is:
Notice that the condition number of the matrix is precisely , which is large for small . This means that one direction (in this case the x-axis) is penalized much more than the other (the y-axis). This leads to stretched out level sets, which leads to zigzags and slow convergence. How can we fix this?
5Newton’s Method (optional)¶
To derive the gradient descent method (GD), we used a first order approximation of near to figure out what direction we should move in. What the last example we saw showed was that when the gradient changes quickly (look at the direction of the gradients in the zizag plot; they are all over the place!), things can go wrong. This suggests that we should also account for how quickly the gradient changes: we need to compute the “gradient of the gradient”, a.k.a. the Hessian of . The Hessian of a function is an symmetric matrix with entries given by order partial derivatives of :
The Hessian tells us how quickly the gradient changes in the same way tells us how quickly changes for a scalar function . The Hessian lets us make a second order Taylor series approximation to our function near our current guess :
which provides a local quadratic approximation to near :
As before, if we let , we can rewrite (14) as
Since we want to make as small as possible, it makes sense to pick to minimize the RHS of (15), which is another minimization problem!
We’ll focus on the setting where is positive definite: this corresponds to settings where our function is convex. In this case, the RHS of (15) is a positive definite quadratic function, which is minimized at:
Using this descent direction instead of yields Newton’s Method:
The idea behind Newton’s Method is to “unstretch” the stretched out directions, so that to our algorithm, the level sets of a function are locally circles. If we look at our test example above, note that:
so that for , we have:
i.e., we converge in one step no matter what the choice of is in !
The cost of this fast convergence though is that at each update, we need to solve a linear system of equations of the form
which may be expensive if is a high-dimensional vector. It is for this reason that gradient descent based methods are the predominant methods used in machine learning, where oftentimes the dimensionality of can be on the order of millions or billions.
