10.X Case Study: Recommender Systems
Collaborative Filtering with SVD

1Learning Objectives¶
By the end of this page, you should know:
- the definition of a recommender system based off of collaborative filtering
- how to express collaborative filtering as a matrix completion problem
- one approach to solve the matrix completion via the singular value decompositon
2Types of Recommender System¶
Recommender systems have become a vital part of our digital lives, guiding us towards products, services, and content we might like. Generally speaking, recommender systems are algorithms designed to suggest relevant items to users. These systems are used in various domains such as e-commerce, streaming services, and social media. They enhance user experience by filtering vast amounts of information to deliver personalized content. There are two main categories of recommender systms:
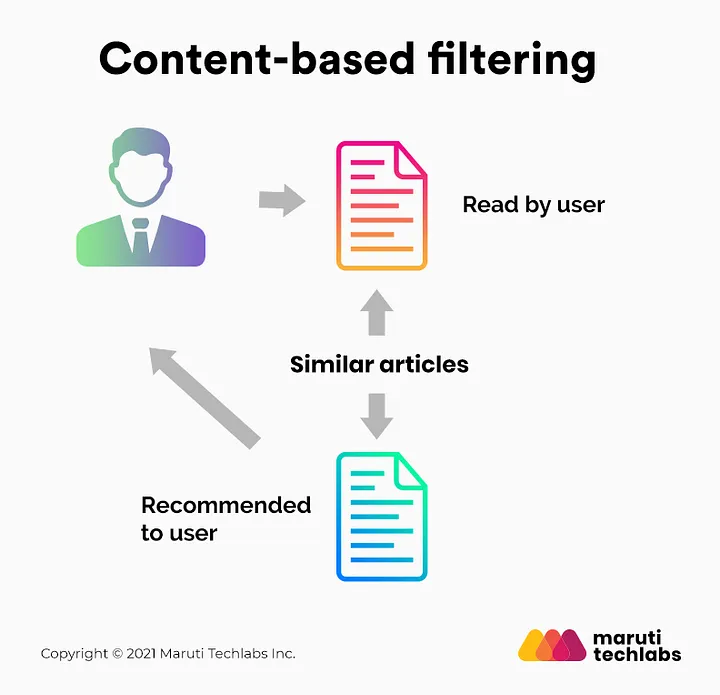
- Content-Based Filtering: Content-based filtering recommends items to users by analyzing the features of items they have previously liked, matching similar items based on those attributes.
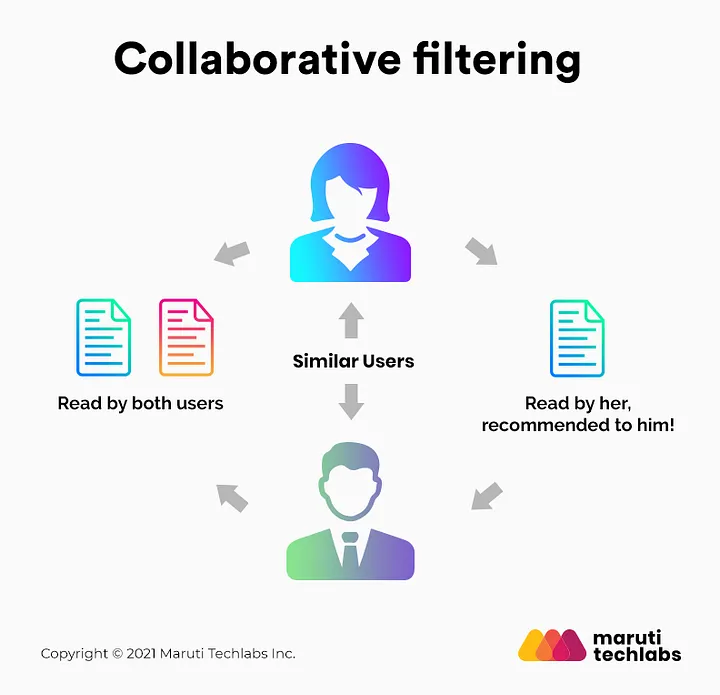
- Collaborative Filtering: Collaborative filtering recommends items to users by identifying patterns and similarities in user behavior and preferences, leveraging the collective data from multiple users to make personalized suggestions.
3Movie Recommendations¶
The tools that we have learned in this class are used in the design of both types of recommender system. In this case study, we will focus on collaborative filtering, where the singular value decomposition plays a critical roll. To start off with, let’s download a dataset consisting of movie ratings from various users.
import urllib.request
from zipfile import ZipFile
import pandas as pd
import numpy as np
urllib.request.urlretrieve("https://files.grouplens.org/datasets/movielens/ml-100k.zip", "data.zip")
file_name = "data.zip"
with ZipFile(file_name, 'r') as z:
# printing all the contents of the zip file
z.printdir()
# extracting all the files
print('Extracting all the files now...')
z.extractall()
print('Done!')
ratings_df = pd.read_table('ml-100k/u.data', header=None, sep=r'\s+').drop(columns=3).rename(columns={0: "users", 1: "movies", 2: "ratings"})
movie_info = pd.read_table('ml-100k/u.item', header=None, sep='|', encoding="iso-8859-1")[[0,1]].rename(columns={0:"movies", 1:"movie titles"})
movie_dict = dict(zip(list(movie_info['movies']), list(movie_info['movie titles'])))
ratings_df['movie_names'] = ratings_df['movies'].apply(lambda x: movie_dict[x])File Name Modified Size
ml-100k/ 2016-01-29 14:26:28 0
ml-100k/allbut.pl 2000-07-19 16:09:28 716
ml-100k/mku.sh 2000-07-19 16:09:28 643
ml-100k/README 2016-01-29 14:26:28 6750
ml-100k/u.data 2000-07-19 16:09:30 1979173
ml-100k/u.genre 2000-07-19 16:09:30 202
ml-100k/u.info 2000-07-19 16:09:30 36
ml-100k/u.item 2000-07-19 16:09:30 236344
ml-100k/u.occupation 2000-07-19 16:09:30 193
ml-100k/u.user 2000-07-19 16:09:30 22628
ml-100k/u1.base 2001-03-08 12:33:08 1586544
ml-100k/u1.test 2001-03-08 12:32:56 392629
ml-100k/u2.base 2001-03-08 12:33:24 1583948
ml-100k/u2.test 2001-03-08 12:33:12 395225
ml-100k/u3.base 2001-03-08 12:33:38 1582546
ml-100k/u3.test 2001-03-08 12:33:26 396627
ml-100k/u4.base 2001-03-08 12:33:52 1581878
ml-100k/u4.test 2001-03-08 12:33:40 397295
ml-100k/u5.base 2001-03-08 12:34:04 1581776
ml-100k/u5.test 2001-03-08 12:33:54 397397
ml-100k/ua.base 2001-03-08 12:34:18 1792501
ml-100k/ua.test 2001-03-08 12:34:18 186672
ml-100k/ub.base 2001-03-08 12:34:34 1792476
ml-100k/ub.test 2001-03-08 12:34:36 186697
Extracting all the files now...
Done!
We loaded a dataframe that the ratings info from a collection of users.
ratings_df.head()Our dataset now consists only of the movie titles, the user id, and the user rating. Below, we’ll look at the number of unique movies, the number of users, the range of the ratings, and the total number of entries in our dataset.
print('Number of movies: ', ratings_df['movies'].nunique())
print('Number of users: ', ratings_df['users'].nunique())
print('Minimum rating: ', np.min(ratings_df['ratings']), ' Maximum rating: ', np.max(ratings_df['ratings']))
print('Number of data points: ', len(ratings_df))Number of movies: 1682
Number of users: 943
Minimum rating: 1 Maximum rating: 5
Number of data points: 100000
Since there are 100000 datapoints, and 943 users, it means that we have reviews for about 80 movies per user on average. This means that on average there are over 1500 movies that haven’t been watched by any given user. Our goal is to help each user to select which of these movies to watch next!
Our first step in doing so will be to arrange the dataset into a matrix, and the users are the rows, and the movies are the columns. For every movie that has been reviewed by a user, we will fill the corresponding entry in the matrix with the ratings given by the user.
We first construct our matrix, called “ratings_matrix”. All entries will be initialized to zero. Then we will iterate through the dataset, and for every (movie, user) pair for which we have a rating, we will add that rating to our matrix.
ratings_matrix = np.zeros((ratings_df['users'].nunique(), ratings_df['movies'].nunique()))
for i in range(100000):
ratings_matrix[ratings_df['users'][i]-1, ratings_df['movies'][i]-1] = ratings_df['ratings'][i]
print(ratings_matrix)[[5. 3. 4. ... 0. 0. 0.]
[4. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
...
[5. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 5. 0. ... 0. 0. 0.]]
As the minimum rating was 1.0, all 0.0 entries are correspond to (user, movie) pairs where no rating was available in our dataset. Our first step to recommend movies to users will be to impute, or fill in, the missing entries.
Without additional assumptions about the data, the imputation of this data can be quite random. Therefore, the standard assumption imposed for collaborative recommender systems is the rankings matrix is of rank .
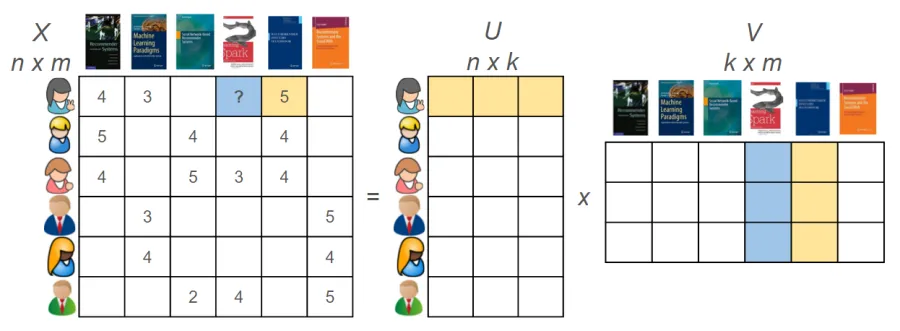
This assumption suggests that if we apply an singular value decomposition to the ratings matrix, there will be relatively few large singular values. Therefore, using the patterns just in the data that is present in the ratings matrix, we may be able to guess values for entries that are missing. Generally, this problem is referred to as low-rank matrix completion. In this case study, we will take a rather simple approach consisting of three steps:
- Fill in the missing entries with some crude guess
- Take the singular value decomposition, and truncate all but singular values.
- Construct an estimate for the ratings matrix using the truncated singular vectors and values.
There are many ways to fill in the missing entries. One option would be to assign the missing entries to have the average rating over all of the entries that are present. Another option would be to assume that users give fairly similar ratings to all movies, and assign missing entries in each row with the average of the existing entries in each row. Alternatively, we could assume that good movies are appreciated by all users, and assign missing entries in each column with the average of the existing entries in the column. We will stick with the last option for the remainder of this case study, but you are encouraged to try the other possibilities and see how the results change if you are curious!
Let’s see what this matrix looks like below.
for i in range(ratings_matrix.shape[1]):
ratings_matrix[:,i][ratings_matrix[:,i] < 1.0] = np.mean(ratings_matrix[:,i][ratings_matrix[:,i] >= 1.0])
print(ratings_matrix)[[5. 3. 4. ... 2. 3. 3. ]
[4. 3.20610687 3.03333333 ... 2. 3. 3. ]
[3.87831858 3.20610687 3.03333333 ... 2. 3. 3. ]
...
[5. 3.20610687 3.03333333 ... 2. 3. 3. ]
[3.87831858 3.20610687 3.03333333 ... 2. 3. 3. ]
[3.87831858 5. 3.03333333 ... 2. 3. 3. ]]
We now see that there are no longer zero entries in the ratings matrix. All missing values have been imputed with a crude guess. Let’s now move on to the second step: taking the SVD of the ratings matrix.
U, Sigma, Vt = np.linalg.svd(ratings_matrix, full_matrices=False)
print('recovery error: ', np.max(np.abs(ratings_matrix - U@np.diag(Sigma)@Vt)))recovery error: 5.231814981243588e-12
Let’s see how the singular values decay by plotting them on a log scale.
import matplotlib.pyplot as plt
plt.plot(Sigma)
plt.yscale('log')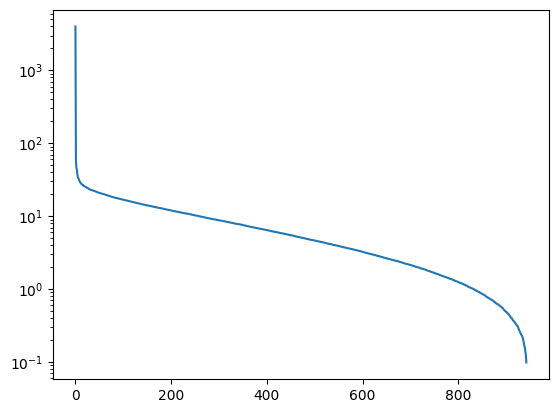
The entries quickly decay in importance after about the first hundred. Let’s try keeping 100 singular values for the reconstruction.
r = 100
reconstruction = U[:,:r]@np.diag(Sigma[:r])@Vt[:r]print(reconstruction)[[4.57855584 3.36739444 4.07027843 ... 2.00518534 3.00777801 3.00777801]
[3.95700992 3.16199831 2.9810728 ... 1.99404691 2.99107036 2.99107036]
[4.07989561 3.21074972 3.07965009 ... 2.00740203 3.01110305 3.01110305]
...
[4.58211541 3.20162489 3.14587845 ... 1.99745256 2.99617884 2.99617884]
[4.19707872 3.10547995 2.8626482 ... 2.00342195 3.00513293 3.00513293]
[3.59635832 4.06925238 3.01920191 ... 2.00957772 3.01436658 3.01436658]]
The result looks quite similar to the crudely imputed matrix from earlier, but with some small deviations. Let’s use the result to recommend movies to a user. To start, we’ll examine the hisotry of ratings by user zero.
user = ratings_df['users'][23]
user_history = ratings_df.loc[ratings_df['users']==user]
print(user_history) users movies ratings movie_names
18 291 1042 4 Just Cause (1995)
23 291 118 2 Twister (1996)
84 291 144 5 Die Hard (1988)
448 291 80 4 Hot Shots! Part Deux (1993)
756 291 686 5 Perfect World, A (1993)
... ... ... ... ...
96563 291 562 4 Quick and the Dead, The (1995)
97186 291 833 3 Bulletproof (1996)
98202 291 1047 2 Multiplicity (1996)
98524 291 508 5 People vs. Larry Flynt, The (1996)
99473 291 573 4 Body Snatchers (1993)
[296 rows x 4 columns]
Now let’s look what our recommender system suggests. To recover the recommendations, we first make a python dictionary mapping the movie index back into the movie name.
The recommendations we make to the user will now be the entries in the user’s row of the reconstruction matrix with the highest score. Let’s print out 20 recommendations for user zero below. Along with each recommendation, we’ll check whether the user has already watched that movie.
best_movies = np.argsort(reconstruction[user-1])[-20:] + 1
for movie in best_movies:
print('Movie suggestion: ', movie_dict[movie], 'already watched? : ', movie in list(user_history['movies']))Movie suggestion: They Made Me a Criminal (1939) already watched? : False
Movie suggestion: Someone Else's America (1995) already watched? : False
Movie suggestion: Marlene Dietrich: Shadow and Light (1996) already watched? : False
Movie suggestion: Entertaining Angels: The Dorothy Day Story (1996) already watched? : False
Movie suggestion: Prefontaine (1997) already watched? : False
Movie suggestion: Star Kid (1997) already watched? : False
Movie suggestion: Great Day in Harlem, A (1994) already watched? : False
Movie suggestion: Scream (1996) already watched? : True
Movie suggestion: Liar Liar (1997) already watched? : True
Movie suggestion: Die Hard (1988) already watched? : True
Movie suggestion: Kingpin (1996) already watched? : True
Movie suggestion: Bound (1996) already watched? : True
Movie suggestion: Reservoir Dogs (1992) already watched? : True
Movie suggestion: Willy Wonka and the Chocolate Factory (1971) already watched? : True
Movie suggestion: Rock, The (1996) already watched? : True
Movie suggestion: Pulp Fiction (1994) already watched? : True
Movie suggestion: Return of the Jedi (1983) already watched? : True
Movie suggestion: Silence of the Lambs, The (1991) already watched? : True
Movie suggestion: Dead Man Walking (1995) already watched? : True
Movie suggestion: Fargo (1996) already watched? : True
We have successfully recommended movies to the user! Some of them have already been watched, some of them are new. Unfortunately, it is impossible to know the effectiveness of our recommendation system unless the user watches some of the recommended movies, and tells us whether they enjoyed the movie or not.
Even within this simple SVD based approach for developing a recommender system, there are many options that we can choose as engineers to tune the performance of the system. The two most critical are 1) the way in which the crude initial imputation is performed, and 2) the rank of the ratings matrix that we should assume.