An internet user’s behavior while surfing the web can be modeled as a Markov chain that captures a random walk on a graph. We start with a simple example of this, and then explain how it can be used to design a search engine.
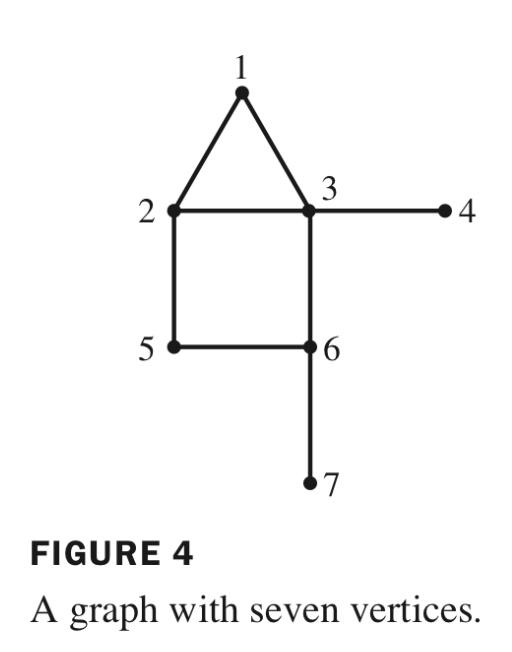
Consider the following graph:
which has seven vertices interconnected by edges. Let’s pretend this graph models a very simple internet! each vertex, or node, is a webpage, and each edge is a hyperlink connecting pages to each other. (For now we assume that if page i links to page j, then page j also links to page i, but this isn’t necessary.) We assume that if a user is on page i, they will click on one of the hyperlinks with equal probability. For example, in our simple internet, if a user is on page 5, they will visit page 2 next 50% of the time and page 6 next 50% of the time. Similarly, if a user is on page 3, they will visit page 1, 2, or 4 next 33% of the time each.
We can model this user behavior using a Markov chain, which is called a simple random walk on a graph. The transition matrix for this graph is given by:
This allows us to answer questions such as the following: suppose 100 users start on page 6. After each user clicks on three hyperlinks, what % of users do we expect to find on each web page. The solution is given by setting our initial user distribution to:
The founders of Google, Sergey Brin and Lawrence Page, reasoned that important pages had links coming from other “important” pages, and thus, a typical internet user would spend more time on more important pages, and less time on less important pages. This can be captured by the steady state distribution x∗ of the Markov chain we are using to model the internet: in the long run, a typical user will spend xi∗ % of their time on page i. This is precisely the observation used to define the Page Rank algorithm, which Google uses to rank the importance of the webpages it catalogs.
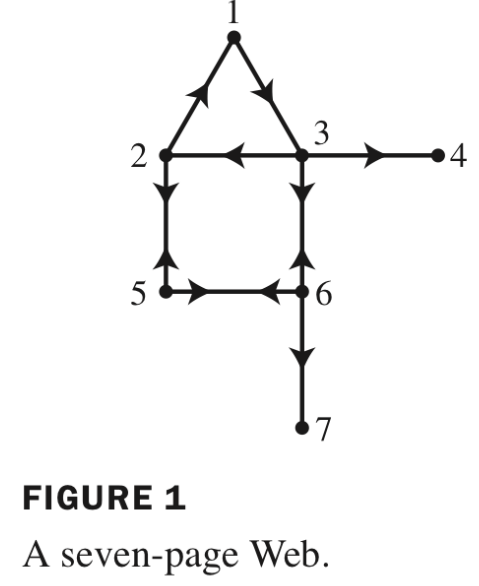
Now, if a typical transition matrix P describing the internet were regular, we would be done - we simply compute x∗=Px∗ and use x∗ to rank websites. Unfortunately, typical models of the web are directed graphs, which lead to non-regular transition matrices P. To address this, Google makes two adjustments, which we illustrate with the following slight modification of our previous example:
The first issue that arises here is that pages 4 and 7 are dangling nodes: if a user ever ends up on page 4 or 7, they never leave as there are no outgoing links. This means that columns 4 and 7 never change as we compute Pk, and hence P cannot be regular. To handle dangling nodes, the following adjustment is made:
The above means that if state j is an absorbing state, we replace column j of P with the vector [n1…n1]. For example, our modified transition matrix is now:
While this helps eliminate dangling nodes, we may still not have a regular transition matrix, as there might still be cycles of pages. For example, if page i only links to page j, and page j only links to page i, a user entering either page is condemned to moving back and forth between the two pages. This means the corresponding columns of P∗k will always have zeros in them, and hence P∗ would not be regular.
In terms of the modified transition matrix P∗, the new transition matrix will be