4.6 Least Squares and Data Fitting
model some observed data
1Reading¶
Material related to this page, as well as additional exercises, can be found in VMLS 13.
2Learning Objectives¶
By the end of this page, you should know:
- what a data fitting problem is and how it relates to least squares
- model parameterization and examples of different parameterizations
- the Minimum Mean Squared Error (MMSE)
- the regression model and one of its application (auto-regressive model for time-series modeling)
- the standard tricks for model selection: generalization and validation
3Introduction¶
We will introduce one of the most important applications of least squares methods: fitting a mathematical model to some relation given some observed data.
A typical data fitting problem takes the following form: There is some underlying feature vector or independent variable and a scalar outcome or response variable that we believe are (approximately) related by some function such that
3.1Data¶
Our goal is to fit (or learn) a model given some data:
These data pairs are sometimes also called observations, examples, samples, or measurements depending on context.
3.2Model Parameterization¶
Our goal is to choose a model that approximates the model well, that is, . The hat notation is traditionally used to highlight that is an approximation to . Specifically, we will write to highlight that is an approximate prediction of the outcome .
In order to efficiently search over candidate model functions , we need to parameterize a model class that is easy to work with. A powerful and commonly used model class is the set of linear in the parameters models of the form
In (LP), the functions are basis functions or features that we choose before hand.
When we solve the data fitting problem, we will look for the parameters that, among other things, make the model prediction consistent with the observed data, i.e., we want .
3.3Data fitting:¶
For the -th observation and the prediction , we define the prediction error or residual .
The least squares data fitting problem chooses the model parameters that minimize the (average of the) sum of the squares of the prediction errors on the data set:
Next we’ll show that this problem can be cast as a least squares problem over the model parameters . Before doing that though, we want to highlight the conceptual shift we are making.
4Data Fitting as Least Squares¶
We start by stacking the outcomes , predictions , and residuals as vectors in :
Then we can compactly write the squared prediction error as . Next, we compile our model parameters into a vector , and build our feature matrix or measurement matrix by setting
The -th column of the matrix is composed of the -th basis function evaluated on each of the data points :
and . In matrix-vector notation, we then have
The least squares data fitting problem then becomes to
over the model parameters , which we recognize as a least squares problem! Assuming we have chosen basis functions such that the columns of are linearly independent (what would it mean if this wasn’t true?), we have that the least squares solution is
5Warm-up: Fitting a Constant Model¶
We start with the simplest possible model and set the number of features and , so that our (admittedly boring) model becomes .
First, we construct by setting . Therefore is the -dimensional all ones vector . We plug this into our formula for :
We have just shown that the mean or average of the outcomes is the best least squares fit of a constant model. In this case, the MMSE is
which is called the variance of , and measures how “wiggly” is.
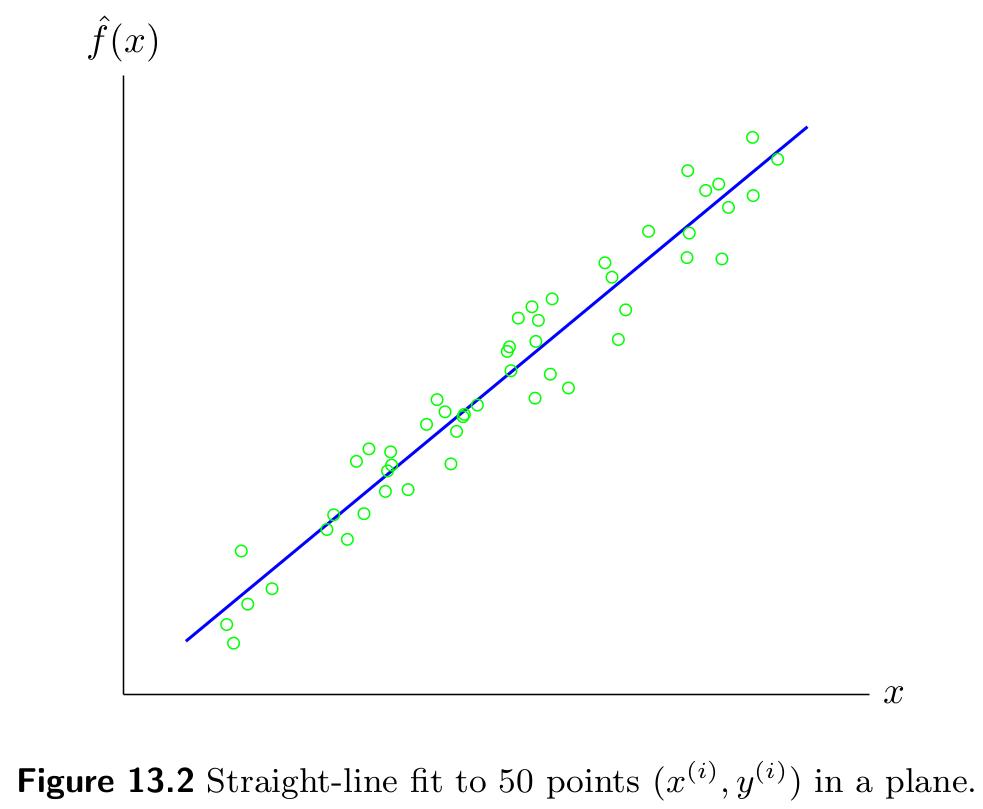
6Univariate Function: Straight Line Fit¶
We start by considering the univariate function setting where our feature vector is a scalar, and hence we are looking to approximate a function . This is a nice way to get intuition because it is easy to plot the data and the model function .
We’ll start with a straight line fit model: we set , with and . In this case our model function is composed of models of the form
Here, we can easily interpret as the y-intercept and as the slope of the straight line model we are searching for.
In this case, the matrix and takes the form
Although we can work out formulas for and , they are not particularly interesting or informative. Instead, we’ll focus on some examples of how to use these ideas. A straight-line fit to 50 data points is given below.
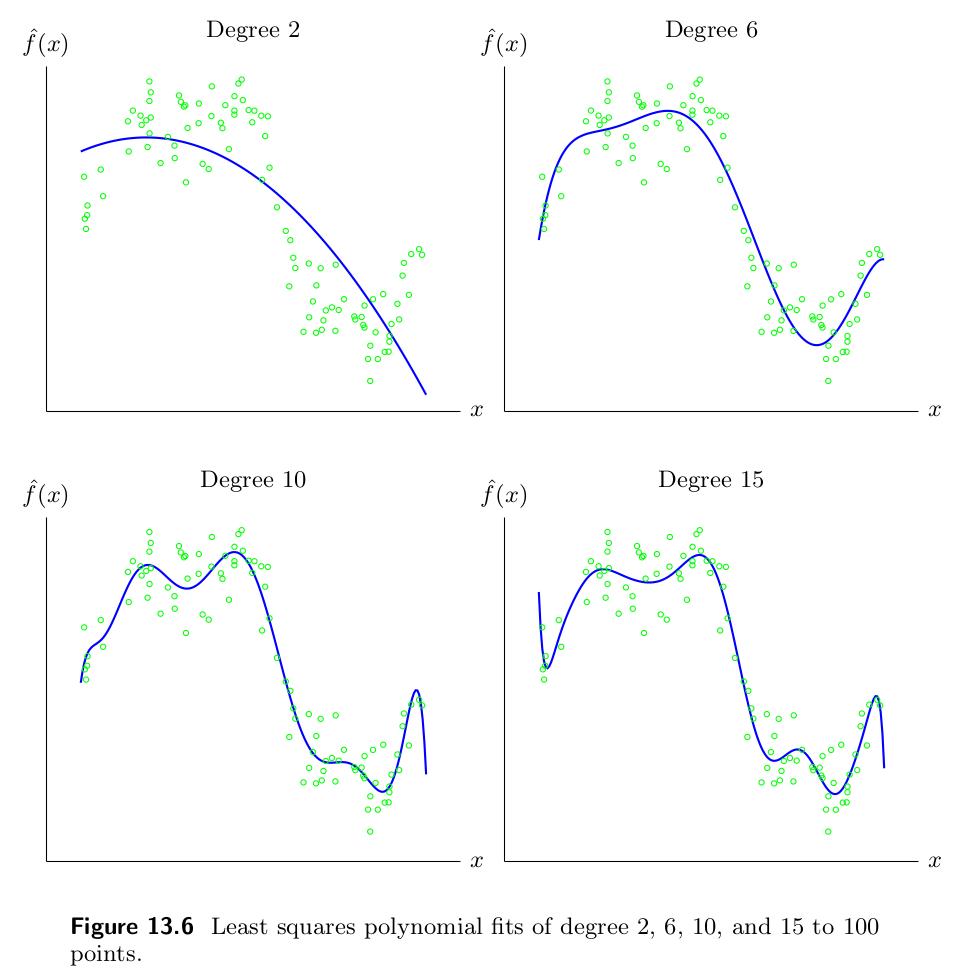
7Univariate Function: Polynomial Fit¶
A simple extension beyond the straight-line fit is a polynomial fit where we set the feature to be
for . This leads to a model class composed of polynomials of at most degree :
In this case, our matrix and takes the form
which you might recognize as a Vandermonde Matrix, which we encountered earlier in the class when discussing polynomial interpolation. An important property of such matrices is that their columns are linearly independent provided that the numbers include at least different values. The figures below show examples of least squares fits of polynomials of degree 2, 6, 10, and 15 to a set of 100 data points.
8Regression Models¶
We now consider the setting of vector-valued independent variables . The analog of a straight-line fit here is a linear regression model of the form:
where and . If we set , then the model becomes:
We can view this as fitting within our general linear in the parameters model by setting and for , so that .
We are of course not obliged to use these features. Instead, suppose that we have features , and assume we have set , as is common done. If we define:
we can write a linear regression model in the new feature vector :
where:
- are the transformed features
- is called the affine term
- is the linear term
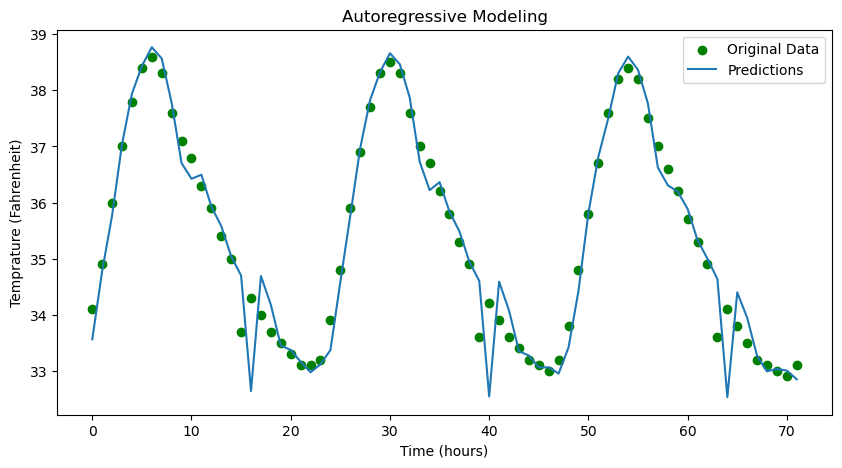
8.1Application: Auto-Regressive Time Series Modeling¶
Here is a very widely used application of the above ideas in the context of time-series forecasting. Our goal here is to fit a model that predicts elements of a time series where is a scalar quantity of interest.
A standard approach is to use an auto-regressive (AR) prediction model:
In equation (AR), the parameter is the memory of the model, and is the prediction of the next value based on the previous observations. We will choose to minimize
We can fit this within our regression model framework by
A little bit of bookkeeping allows us to conclude that we have examples and features.
Python break!¶
In the following code, we show how to fit an auto-regressive model to an online temperature data set that is given in an excel sheet (.csv file). Typically, such large data sets are stored as pandas DataFrame in Python. We convert the pandas DataFrame to numpy format and create our data for the auto-regressive model for a given memory. Then, we use np.linalg.lstsq to solve the least squares problem as we did before.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Data source: https://www.ncei.noaa.gov/cdo-web/search
# Read CSV file into pandas DataFrame
df = pd.read_csv('LGA_temp.csv') # Temperature at LGA airport for 2010 (12 months)
temp = df['HLY-TEMP-NORMAL'].to_numpy()
memory = 8
T = temp.size
N = T - memory
# Function to create the dataset for AR model
def create_data(data, M):
X, y = [], []
for i in range(M, len(data)):
X.append(data[i-M:i])
y.append(data[i])
return np.array(X), np.array(y)
# Create lagged dataset
X_data, y_data = create_data(temp, memory)
theta, residual, rank, sing_val = np.linalg.lstsq(X_data, y_data, rcond=None)
y_pred = X_data @ theta
print("RMS error: ", np.sqrt(residual/N))
# Plot predictions
plot_hours = 24*3 # first 3 days of 2010
plt.figure(figsize=(10, 5))
plt.scatter(np.arange(plot_hours), y_data[:plot_hours], color='green', label='Original Data')
plt.plot(y_pred[:plot_hours], label='Predictions')
plt.xlabel('Time (hours)')
plt.ylabel('Temprature (Fahrenheit)')
plt.title('Autoregressive Modeling')
plt.legend()
plt.show()RMS error: [0.34101808]
9Model Selection, Generalization, and Validation¶
This section is entirely practical: these are standard “tricks of the trade” that you will revisit in more detail in mae advanced classes on statistics and machine learning.
Our starting point is a philosophical question: what is the foul of a learned model? Perhaps surprisingly, it is NOT TO PREDICT OUTCOMES FOR THE GIVEN DATA; after all, we already have this data! Instead, we want to predict the outcome on new, unseen data.
If a model makes reasonable predictions on new unseen data, it is said to generalize. On the other hand, a model that makes poor predictions on new unseen data, but predicts the given data well, is said to be over-fit.
Then, we only use the training data to fit (or “train”) our model, and then evaluate the model’s performance on the test set. If the prediction errors on the training and test sets are similar, then we guess the model will generalize. This is rarely guaranteed, but such a comparison is often predictive of a model’s generalization properties.
Validation is often used for model selection, ie., to choose among different candidate models. For example, by comparing train/test errors, we can select between;
- Polynomial models of different degrees.
- Regression models with different sets of features
- AR models with different memories.
Python break!¶
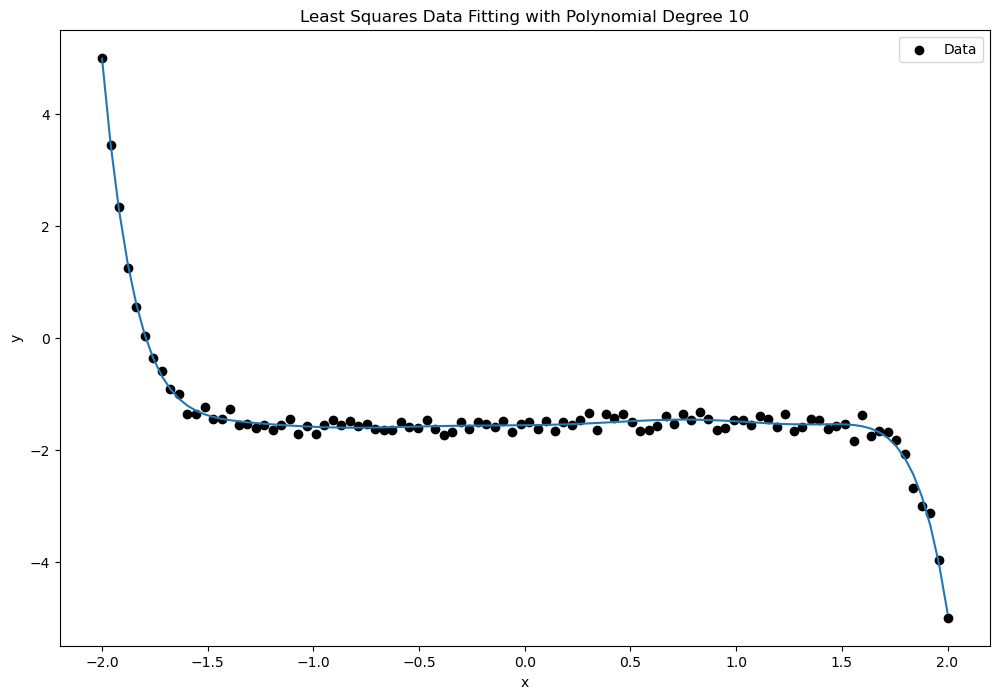
In the following code, we use the polyfit function from the Polynomial libray in Python to fit a polynomial model by solving the corresponding least squares problem. We compare the RMS error and the quality of fit for varying degrees of polynomial using synthetic data.
import numpy as np
import matplotlib.pyplot as plt
from numpy.polynomial.polynomial import Polynomial
# Generate synthetic data
np.random.seed(334)
x = np.linspace(-2, 2, 100)
y = -0.5*x**13 + x**10 + 2*x**9 - x**7 + 0.3*x**6 - 3*x**4 + 2 * x**3 - 5 * x**2 + 3 * x + np.random.normal(0, 10, size=x.shape)*7
y_data = ((y - min(y))/(max(y) - min(y)))*10 - 5 # scaling to [-5, 5]
# Function to fit and plot polynomials of varying degrees
def fit_and_plot_polynomial(x, y, degrees):
for degree in degrees:
# Fit polynomial of given degree
p, results = Polynomial.fit(x, y, degree, full=True) # results[0] is residuals
y_fit = p(x)
print(f'RMS for Degree {degree}: ', np.sqrt(results[0]/y.size))
plt.figure(figsize=(12, 8))
plt.scatter(x, y, label='Data', color='black')
# Plot the polynomial fit
plt.plot(x, y_fit)
plt.xlabel('x')
plt.ylabel('y')
plt.title(f'Least Squares Data Fitting with Polynomial Degree {degree}')
plt.legend()
plt.show()
# Degrees of polynomials to fit
degrees = [2, 4, 8, 10]
# Fit and plot polynomials
fit_and_plot_polynomial(x, y_data, degrees)RMS for Degree 2: [0.89961455]
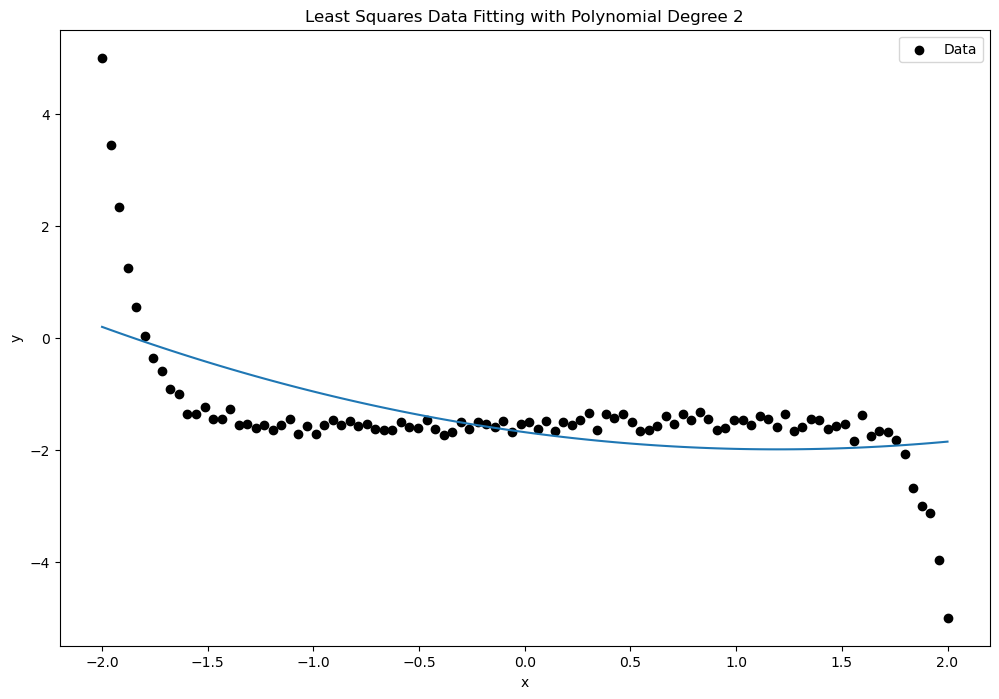
RMS for Degree 4: [0.53118696]
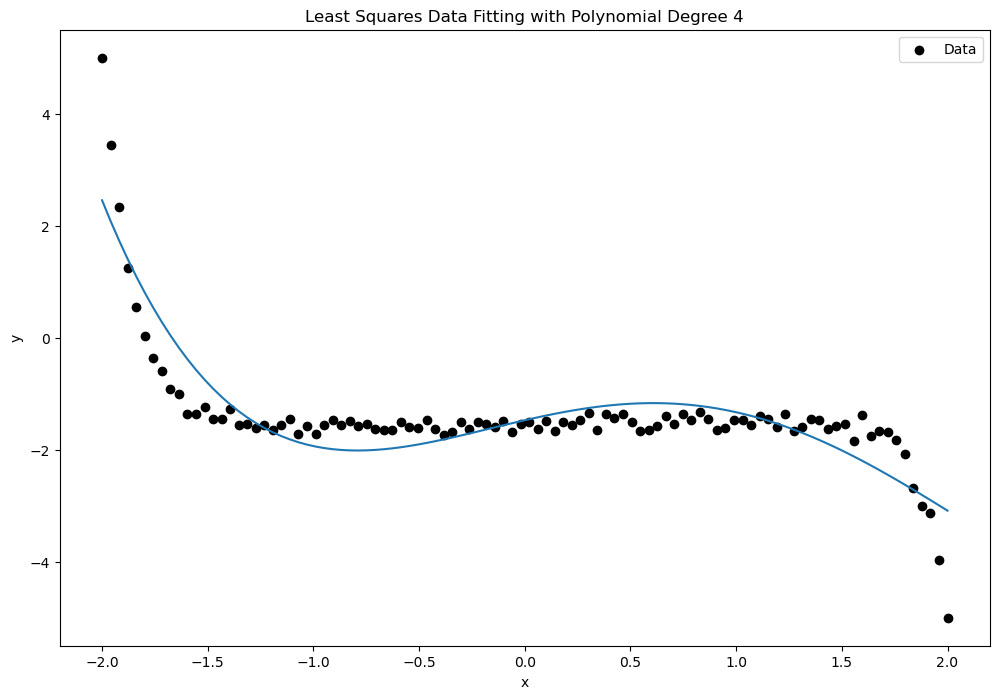
RMS for Degree 8: [0.12656145]
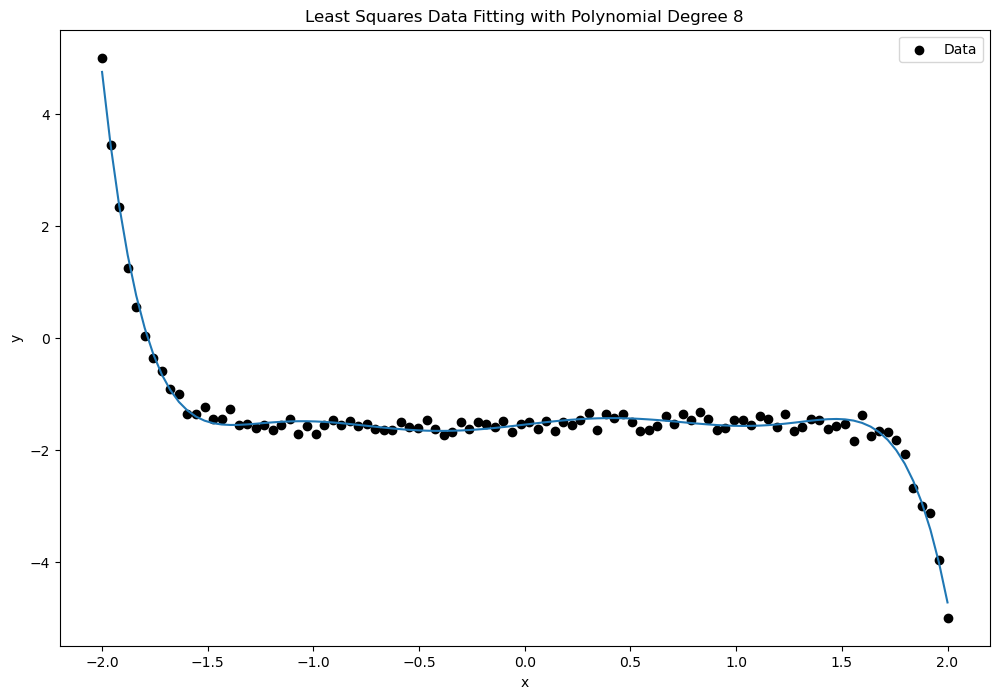
RMS for Degree 10: [0.10145153]