13.4 Stochastic Gradient Descent
1Learning Objectives¶
By the end of this page, you should know:
- why naive backpropagation is computationally inefficient
- the Stochastic Gradient Descent Algorithm
- what is Perceptron and how it is used for linear classification
- single and multilayer perceptrons, and the importance of activiation functions
2Naive Backpropagation¶
In the previous lecture, motivated by machine learning applications, we discussed how to apply gradient descent to solve the following optimization problem:
over the parameters of a model so that for all training data input/output pairs , .
The bulk of our effort was spent on understanding how to compute the gradient of with respect to the model parameters , with a particular focus on models that can be written as the following composition of models:
which is the structure of contemporary models used in machine learning called deep neural networks (we’ll talk about these much more in this lecture). We made two key observations about the model structure that allowed us to effectively apply the matrix chain rule to compute gradients :
only needs to compute partial derivatives of and layers ;
If we start from layer and work our way backwards we can (i) reuse previously computed partial derivatives, and (ii) save space on memory by exploiting that is a row-vector.
The resulting algorithm is called backpropagation, and is a key enabling technology in modern machine learning. You will learn more about this in ESE 5460.
Now, despite all of this cleverness, when the model parameter vectors and layer outputs are very high dimensional (it is not uncommon for each to have 100s of thousands or even millions of components) computing the gradient of a single term in the sum (1) can be quite costly. Add to that the fact that the number of data points is often very large (order of millions in many settings), and we quickly run into some serious computational bottlenecks. And remember, this all just so we can run a single iteration of gradient descent. This may seem hopeless, but luckily, there is a very simple trick that lets us work around this problem: stochastic gradient descent.
3Stochastic Gradient Descent (SGD) Algorithm¶
Stochastic Gradient Descent (SGD) is the work horse algorithm of modern machine learning and has been rediscovered by various communities over the past 70 years, although it is usually credited to Robbins and Monro for a paper they wrote in 1951.
The SGD algorithm can be summarized as follows: Start with an initial guess , and at each iteration , do:
(i) Select an index at random (ii) Update
Using the gradient of only the loss term .
As before, is a step-size that can change as a function of the current iterate.
This method works shockingly well in practice and is computationally tractable as at each iteration, the gradient of only the loss term needs to be computed. Modern versions of this algorithm replace step (i) with a mini-batch, i.e., by selecting indices at random, and step (ii) replaces with the average gradient:
The overall idea behind why SGD works (take ESE 6050 if you want to see a rigorous proof) is that while each individual update (SGD) may not be an accurate gradient for the overall loss function loss, we are still following “on average”. This also explains why you may want to use a mini-batch to compute a better gradient estimate (5), as having more loss terms leads to a better approximation of the true gradient. The tradeoff here is that as becomes larger, computing (5) is more computationally demanding.
4Linear Classification and the Perceptron¶
An important problem in machine learning is that of binary classification. In one of the case studies, you saw how to use least squares to solve this problem. Here, we offer an alternate perspective that will lead us to one important historical reason for the emergence of deep neural networks.
The problem set up for linear binary classification is as follows. We are given a set of vectors with associated binary labels . The objective in linear classification is to find an affine function , defined by unknown parameters and , that strictly separates the two classes. We can pose this as finding a feasible solution to the following linear inequalities:
The geometry of this problem is illustrated below.
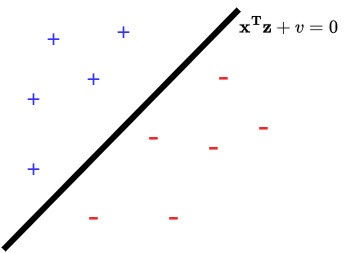
There are three key components:
- The separating hyperplane . This is the set of vectors that lie on the subspace , which is the solution set to the linear equation
The coefficient matrix here is , and so rank Col. This tells us that . In , this is the equation of a line:
In , this is the equation of a plane with normal vector going through point and in is called a hyperplane. A key feature of a hyperplane is that it splits into two half-spaces, i.e., the subsets of on either side.
The half-space , which is the “half” of for which . We want all of our positive examples to live here.
The half-space , which is the “half” of for which . We want all examples to live here.
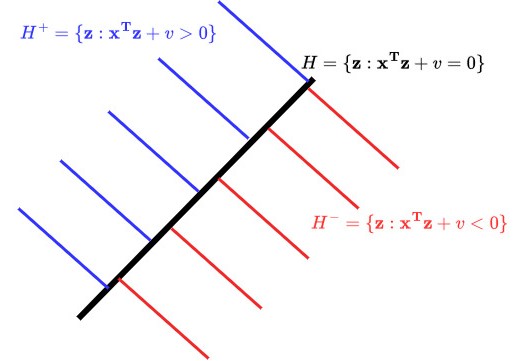
The problem of finding the parameters defining the classifier in (6) can be solved using linear programming, a kind of optimization algorithm that you’ll learn about in ESE 3040 and ESE 6050. It can also be solved using SGD as applied to a special loss function called the hinge loss:
which is a commonly used loss function for classification (you’ll learn why in your Machine Learning classes).
The reason we are taking this little digression is that applying SGD to the hinge loss gives us The Perceptron Algorithm:
- Initialize initial guess
- For each iteration , do:
- Draw a random index
- If : Update
This algorithm goes through the examples one at a time, and updates the classifier only when it makes a mistake (10). The intuition is it “nudges” the classifier to be “less” wrong by on any example it currently misclassifies.
This incremental update works, and you can show that if there exists a solution to (6), the perceptron algorithm will find it. People got REALLY EXCITED ABOUT THIS! See below for a NYT article about the perceptron algorithm, which in hindsight seems a little silly given that we now know it’s just SGD applied to a particular loss function. But then again, so is most of today’s AI!

5Single and Multi Layer Perceptrons¶
Given the excitement about the Perceptron, why do we not use them anymore? It turns out, it is very easy to stump! Consider the following set of positive and negative examples:
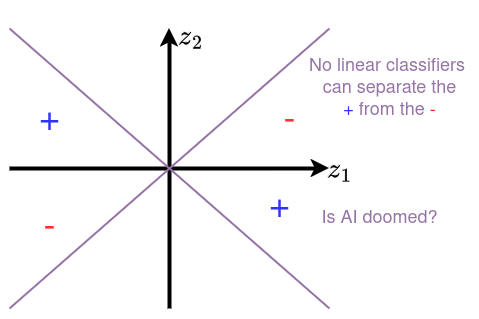
These define an XOR function: the positive examples are in quadrants where and the negative ones are in quadrants for which . These can’t be separated by a linear classifier!
But suppose we were allowed to have two classifiers, and then combine them using a nonlinearity?
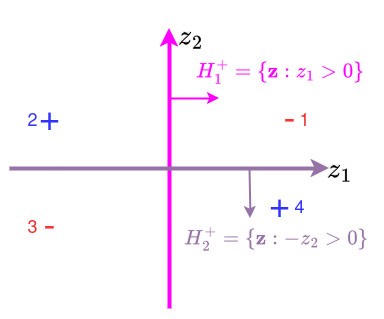
In the image above, we define a pink classifier that returns , a purple classifier that returns . If we define our output to be
then we see that this ‘works’:
Table 1:Nonlinear classifier
| 1 | 2 | 3 | 4 | |
|---|---|---|---|---|
| Sign | +1 | -1 | -1 | +1 |
| Sign | -1 | -1 | +1 | +1 |
| Sign | -1 | +1 | -1 | +1 |
This ‘worked’! The two key ingredients here are:
- Having intermediate computation, called hidden layers
- Allowing for some nonlinearity.
These two ingredients are combined to define the Multilayer Perceptron (MLP).
In practice, (12) is trained to find using SGD and backpropagation.
Some common activation functions include:
- The Sigmoid function:
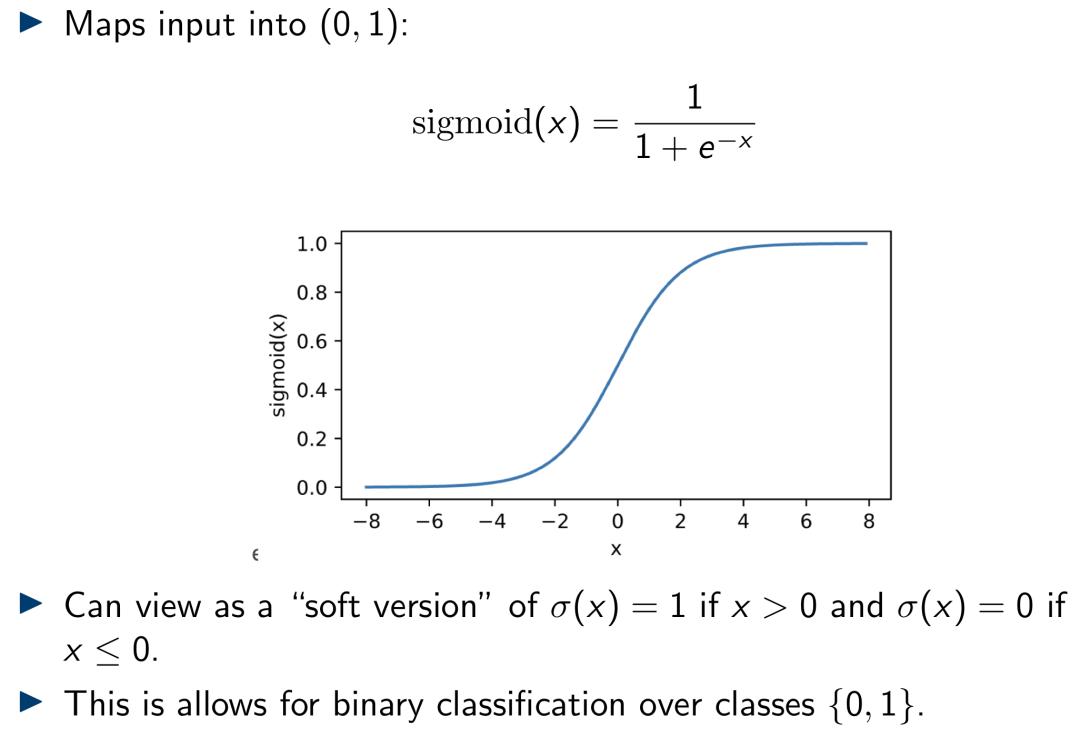
- The Rectified Linear Unit (ReLU):
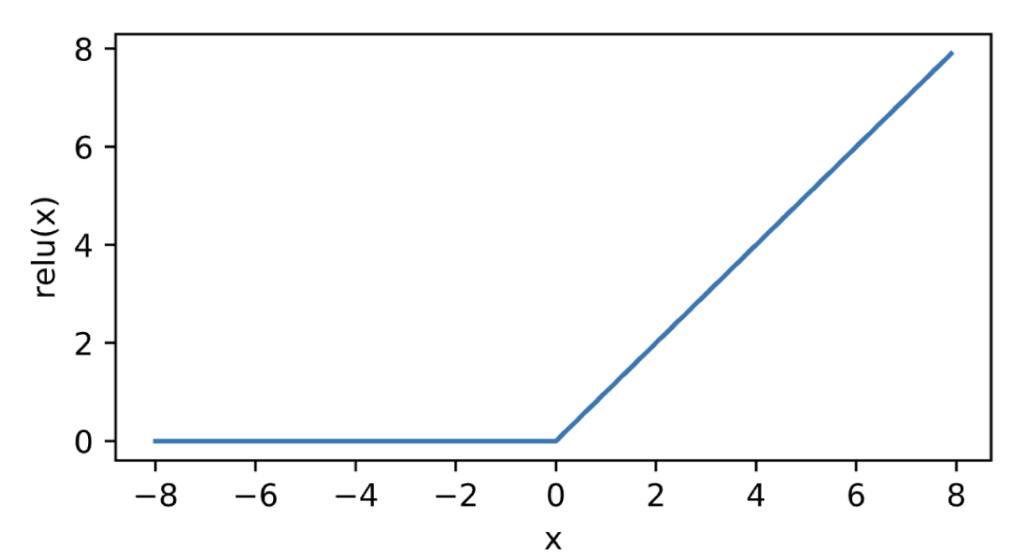
Which activation function to use is a bit of an art, but there are generally accepted tricks of the trade that you’ll learn about in ESE 5460. There are also many more than these two, with new ones being invented.
6Deep MLPs¶
There is nothing preventing us from adding more hidden layers. The -hidden-layer MLP is defined as:
Shown below is an example with 3 hidden layers.
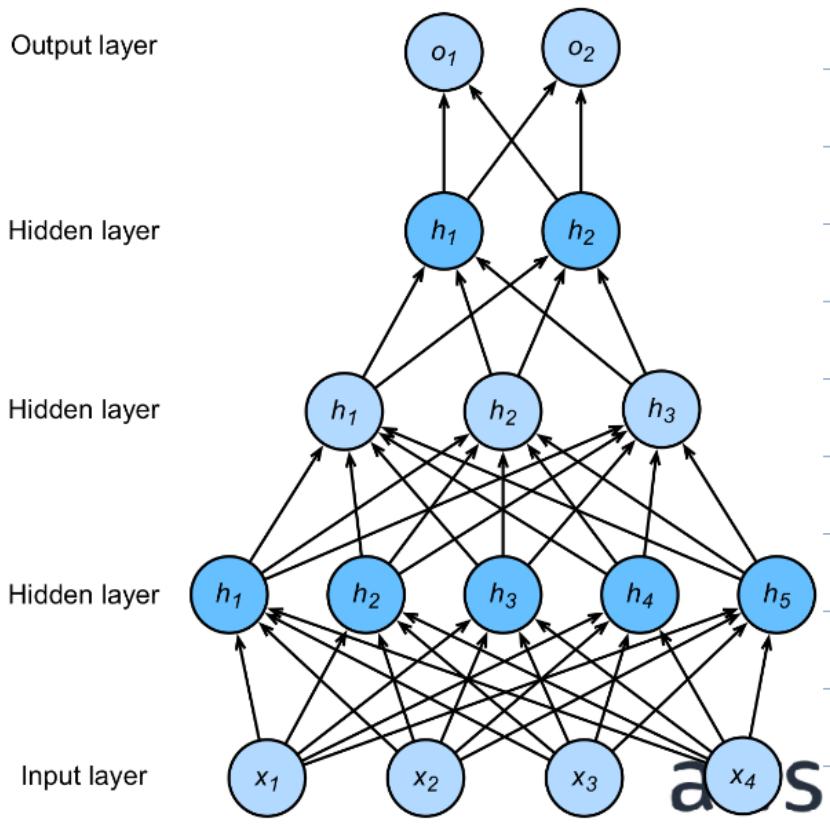
The important thing to notice is these functions are compatible with our discussion on backpropagation, meaning computing gradients with respect to the parameters can be done efficiently!
6.1Python Break: Autodifferentiation in PyTorch!¶
In this example, we’ll show how to take advantage of autodifferentiation in the PyTorch machine learning library in order to efficiently train machine learning models in code.
For our first example, we will take a look at logistic regression. In logistic regression, we have the following:
A dataset of pairs of the form , where is a vector with real-valued entries, and is a boolean-valued label.
A class of models of “logistic functions”, where , , and . A few things to note; the range of any logistic function is , i.e., these logistic functions only output values between 0 and 1; this is good when we want to learn boolean-valued labelings of our data. Also, try to convince yourself that for any value , the set of all such that is the solution set to an inhomogenous linear system. Furthermore, convince yourself that the set of all such that is the solution to a homogeneous linear system; we will call this set the decision boundary.
A binary cross-entropy loss (or log-loss) function which measures the loss of our model on the dataset , defined by:
To give some high-level intuition, the binary cross-entropy loss is smaller when, on average, the values of are close to . This has a very nice interpretation in terms of probabilities, but for now we will focus on the optimization aspects of logistic regression.
In many machine learning scenarios, the objective is to choose the model with the lowest loss on the dataset (this is known as empirical risk minimization). In our scenario, we can formulate this as an optimization problem:
In the case of logistic regression with log-loss, this is actually a convex loss which means that gradient descent will find the global minimum (if done correctly)! This is exactly what the code snippet below is doing; note that we labeled each section of the code; we will explain what each section does in a bit.

# We need to install the required software packages for deep learning: this will take about 10min
%pip install torch torchvisionRequirement already satisfied: torch in /opt/anaconda3/envs/books/lib/python3.12/site-packages (2.4.0)
Requirement already satisfied: torchvision in /opt/anaconda3/envs/books/lib/python3.12/site-packages (0.19.0)
Requirement already satisfied: filelock in /opt/anaconda3/envs/books/lib/python3.12/site-packages (from torch) (3.15.4)
Requirement already satisfied: typing-extensions>=4.8.0 in /opt/anaconda3/envs/books/lib/python3.12/site-packages (from torch) (4.11.0)
Requirement already satisfied: sympy in /opt/anaconda3/envs/books/lib/python3.12/site-packages (from torch) (1.13.0)
Requirement already satisfied: networkx in /opt/anaconda3/envs/books/lib/python3.12/site-packages (from torch) (3.3)
Requirement already satisfied: jinja2 in /opt/anaconda3/envs/books/lib/python3.12/site-packages (from torch) (3.1.4)
Requirement already satisfied: fsspec in /opt/anaconda3/envs/books/lib/python3.12/site-packages (from torch) (2024.6.1)
Requirement already satisfied: setuptools in /opt/anaconda3/envs/books/lib/python3.12/site-packages (from torch) (70.0.0)
Requirement already satisfied: numpy in /opt/anaconda3/envs/books/lib/python3.12/site-packages (from torchvision) (1.26.4)
Requirement already satisfied: pillow!=8.3.*,>=5.3.0 in /opt/anaconda3/envs/books/lib/python3.12/site-packages (from torchvision) (10.3.0)
Requirement already satisfied: MarkupSafe>=2.0 in /opt/anaconda3/envs/books/lib/python3.12/site-packages (from jinja2->torch) (2.1.5)
Requirement already satisfied: mpmath<1.4,>=1.1.0 in /opt/anaconda3/envs/books/lib/python3.12/site-packages (from sympy->torch) (1.3.0)
Note: you may need to restart the kernel to use updated packages.
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
torch.manual_seed(541)
# (A) Generate a random dataset
X = torch.rand(1000, 2)
Y = torch.round(0.25 * X[:, 0] + 0.45 * X[:, 1] + 0.3 * torch.rand(1000))
# (B) Define a logistic regression model using a single linear layer
class LogisticRegressionModel(nn.Module):
def __init__(self):
super(LogisticRegressionModel, self).__init__()
self.a = nn.Parameter(torch.zeros(2))
self.b = nn.Parameter(torch.tensor(0.0))
def forward(self, x):
return torch.sigmoid(torch.matmul(x, self.a.T) + self.b)
# (C) Instantiate the model
model = LogisticRegressionModel()
# (D) Define the loss function and optimizer
criterion = nn.BCELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# (E) Train the model
num_epochs = 10000
for epoch in range(num_epochs):
# Forward pass
outputs = model(X)
loss = criterion(outputs, Y)
# Backward pass and optimization
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Print loss every 1000 epochs
if (epoch+1) % 1000 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
# (F) Testing the model
with torch.no_grad():
predicted = model(X)
predicted_labels = predicted.round()
accuracy = (predicted_labels.eq(Y).sum().item()) / Y.size(0)
print(f'Accuracy: {accuracy * 100:.2f}%')
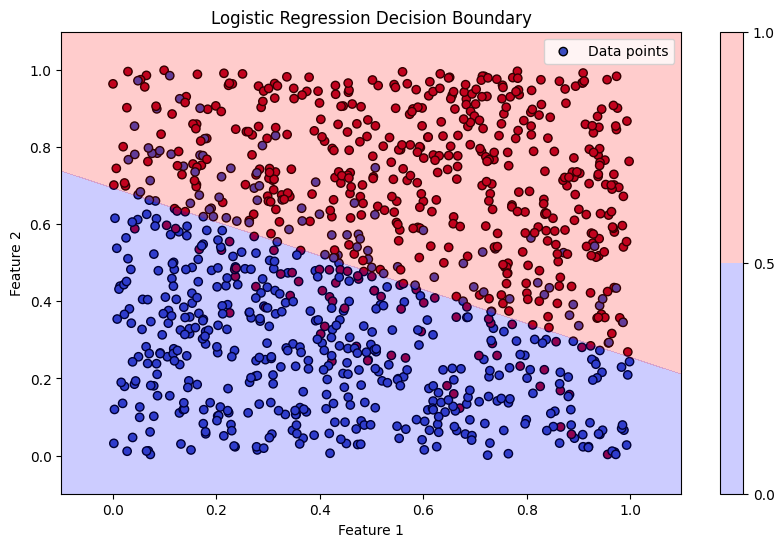
# (G) Plotting the dataset, labels, and decision boundary
plt.figure(figsize=(10, 6))
plt.scatter(X[:, 0], X[:, 1], c=Y.squeeze(), cmap='coolwarm', marker='o', edgecolor='k', label='Data points')
x1_min, x1_max = X[:, 0].min() - 0.1, X[:, 0].max() + 0.1
x2_min, x2_max = X[:, 1].min() - 0.1, X[:, 1].max() + 0.1
xx1, xx2 = np.meshgrid(np.linspace(x1_min, x1_max, 100), np.linspace(x2_min, x2_max, 100))
grid_tensor = torch.tensor(np.c_[xx1.ravel(), xx2.ravel()], dtype=torch.float32)
with torch.no_grad():
probs = model(grid_tensor).reshape(xx1.shape)
plt.contourf(xx1, xx2, probs, levels=[0, 0.5, 1], alpha=0.2, colors=['blue', 'red'])
plt.colorbar()
plt.title('Logistic Regression Decision Boundary')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend(loc='upper right')
plt.show()Epoch [1000/10000], Loss: 0.6212
Epoch [2000/10000], Loss: 0.5708
Epoch [3000/10000], Loss: 0.5320
Epoch [4000/10000], Loss: 0.5018
Epoch [5000/10000], Loss: 0.4778
Epoch [6000/10000], Loss: 0.4583
Epoch [7000/10000], Loss: 0.4424
Epoch [8000/10000], Loss: 0.4291
Epoch [9000/10000], Loss: 0.4180
Epoch [10000/10000], Loss: 0.4085
Accuracy: 83.70%
Here, we’ll explain what each labeled section does and connect these functions to ideas we have already learned:
(A) This is just generating a random dataset.
(B) Here, we define a model class. Logistic models, which we have denoted by , are parameterized by two weights: and . We indicate that this are weights that the optimizer should optimize over by declaring them as
nn.Parameter. (Thetorch.tensorclass is an analog tonp.array.) Theforwardfunction evaluates our function on a batch of data, i.e., evaluates its output on a bunch of points at once; this is done for computational efficiency reasons.(C) Here, we are generating an instance of our model with initial weights set to zero.
(D) Here, we indicate that we want to use the gradient descent algorithm to fit and such as to minimizer the binary cross entropy loss on our dataset. One small note: while the name of the optimizer is
SGD, the way we use it (by running the model on the entire dataset and the computing the gradient with respect to the weights) is actually more akin to gradient descent, which uses the entire dataset.(E) Here, we actually train the model using SGD. The lines
optimizer.zero_grad()andloss.backward()calculate the gradient of the loss function with respect to the weights. This is done completely via autodifferentiation; during the forward pass of the model (where we calloutputs = model(X), which uses theforwardfunction we defined),PyTorchautomatically calculates the gradient of the model outputs with respect to the weights! In the lineloss = criterion(outputs, Y),PyTorchthen finds the gradient of the loss with respect to the model output! Then, the lineoptimizer.step()updates the weights of the model (using the multivariate chain rule) with the learning rate of0.01specified earlier. We repeat this 10000 times, and see that the loss approximately decreases with each iteration.(F) & (G) Here, we test the model and visualize the learned decision boundary compared to the true labelings of the dataset. Looks like we did pretty good! One note: you might notice the
with torch.no_grad()line; usually,PyTorchcomputes gradients of the model outputs with respect to the inputs, but even with the optimized autodifferentiation package, this can be a costly procedure. Luckily, we only need to do this during the training phase! During test time, when we aren’t actively updating the weights of our model, we can tellPyTorchto not compute gradients using thewith torch.no_grad()specifier.
As you can see, we have already learned many of these ideas! We just translated them to code.
For our second example, we’ll see how we can extend these ideas to training multilayer perceptrons (also known as neural networks). Just as in the example above, a neural network is just a parameterized function which takes in a scalar/vector/matrix/tensor as input and produces a scalar/vector/matrix/tensor as output! Below, we have a Python snippet where we train a special type of multilayer perceptron known as a convolutional neural network to classify handwritten digits:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
# (A) Data Preparation
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=64, shuffle=True)
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
testloader = DataLoader(testset, batch_size=64, shuffle=False)
# (B) Define the CNN Model
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
self.dropout = nn.Dropout(p=0.5)
def forward(self, x):
x = torch.relu(torch.max_pool2d(self.conv1(x), 2))
x = torch.relu(torch.max_pool2d(self.conv2(x), 2))
x = x.view(-1, 320)
x = torch.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return torch.log_softmax(x, dim=1)
# (C) Initialize the model, loss function, and optimizer
model = SimpleCNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
# (D) Training the Model
num_epochs = 5
for epoch in range(num_epochs):
running_loss = 0.0
for i, (inputs, labels) in enumerate(trainloader, 0):
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch + 1}: Loss {running_loss / (i + 1):.3f}')
print('Finished Training')
# (E) Testing the Model and Collecting Predictions
correct = 0
total = 0
all_images = []
all_labels = []
all_preds = []
with torch.no_grad():
for inputs, labels in testloader:
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# Collect images and predictions for visualization
all_images.append(inputs)
all_labels.append(labels)
all_preds.append(predicted)
print(f'Accuracy on the 10,000 test images: {100 * correct / total:.2f}%')
# (F) Visualize a Few Images with Predictions
# Convert the list of tensors to one large tensor
all_images = torch.cat(all_images)
all_labels = torch.cat(all_labels)
all_preds = torch.cat(all_preds)
# Define a helper function to unnormalize and plot images
def imshow(img, label, pred, ax):
img = img / 2 + 0.5 # Unnormalize
npimg = img.numpy()
ax.imshow(npimg, cmap='gray')
ax.set_title(f'True: {label}, Pred: {pred}')
ax.axis('off')
# Create subplots
fig, axes = plt.subplots(2, 3, figsize=(8, 8))
axes = axes.flatten()
# Plot some correctly classified images
correct_indices = (all_labels == all_preds).nonzero(as_tuple=True)[0]
incorrect_indices = (all_labels != all_preds).nonzero(as_tuple=True)[0]
# Plot 3 correct and 3 incorrect classifications
for i, ax in enumerate(axes[:3]):
idx = correct_indices[i].item()
imshow(all_images[idx][0], all_labels[idx].item(), all_preds[idx].item(), ax)
for i, ax in enumerate(axes[3:6]):
idx = incorrect_indices[i].item()
imshow(all_images[idx][0], all_labels[idx].item(), all_preds[idx].item(), ax)
plt.tight_layout()
plt.show()Epoch 1: Loss 0.423
Epoch 2: Loss 0.147
Epoch 3: Loss 0.112
Epoch 4: Loss 0.095
Epoch 5: Loss 0.085
Finished Training
Accuracy on the 10,000 test images: 97.59%

Here, we see that our model achieves 97% accuracy on previously unseen data, which is pretty good! Above, we have a few examples of images that the model correctly and incorrectly classified.
To conclude, let’s appreciate how easy PyTorch and autodifferentiation makes it to train deep neural networks. All we need to do is specify the free parameters of our model, and PyTorch automatically computes gradients!